Chọn công nghệ nào khi xử lý dữ liệu ?
Hiện nay, tôi thấy nhiều người, nhiều doanh nghiệp luôn "nổ" rằng mình xử lý dữ liệu lớn, xử lý dữ liệu với các công nghệ hàng đầu. Trong khi, dữ liệu lớn như nào, lớn bao nhiêu, tốc độ tăng trưởng dữ liệu là bao nhiêu thì không thấy nói.
Công nghệ tốt khi nó được sử dụng đúng chỗ, đúng cách. Đừng lấy dao mổ trâu ra để thịt gà

Đừng lấy dao mổ trâu ra để thịt gà
Thôi nói vui vậy thôi chứ công việc của sale là phải thế mà :D :D
Vào chủ đề chính, Chúng ta nên chọn những công cụ nào để phân tích hay bóc ta dữ liệu từ dữ liệu thô.
Công nghệ đầu tiên ai cũng nghĩ tới đó là Hadoop
#1. Hadoop
1.1. Giới thiệu
Ngắn gọn mà nói thì Hadoop gồm có 2 phần chính là HDFS - hệ thống lưu trữ file phân tán và Map-Reduce - Một hệ thống dựa trên YARN dành cho việc xử lý song song lượng lớn các tập dữ liệu. Các bạn có thể đọc chi tiết tại đây
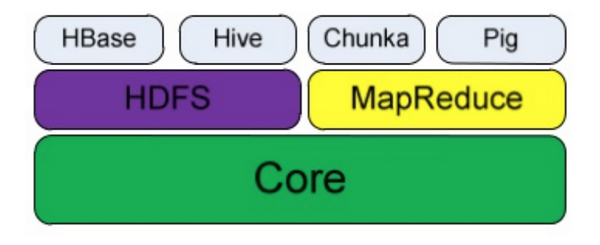
Cấu trúc của các thành phần của Hadoop
1.2. Khi nào thì nên dùng
- Khi bạn muốn lưu trữ dữ liệu một cách an toàn mà không muốn phải sử dụng RAID.
- Khi bạn đang thiết kế hệ thống xử lý phân tán mà bạn có thể query dữ liệu từ 1 server mà dữ liệu không có trên đó.
- Khi bạn muốn xử lý mọi thứ trên file thay vì CSDL truyền thống :D
- Khi bạn muốn có một hệ thống lưu trữ vừa tiết kiệm về chi phí lại có thể mở rộng theo chiều ngang mà không sợ server đã hết slot cắm ổ cứng.
Hadoop có dùng để tính toán được không ? Câu trả lời là Có. Bạn có thể dùng MapReduce để tính toán nhưng giờ đây người ta đã ít dùng đi vì chậm vì tốc độ tính toán phụ thuộc và tốc độc đọc ghi của ổ cứng và việc code nó khá phức tạp phải định nghĩa hay code map như nào và reduce như nào.
Để giải quyết 2 vấn đề đó thì Spark được sinh ra.
#2. Spark
2.1. Giới thiệu
Spark là một framework tính toán phân tán hay nói cách khác Spark là một framework giúp bạn tính toán song song trên nhiều máy/server.
2.2. Khi nào nên dùng
- Khi bạn có dữ liệu hàng chục GB trở lên.
- Khi bạn phải join, sum,... cả trăm triệu hay cả tỉ bản ghi.
- Khi bạn muốn áp dụng các thuật toán ML cùng với dữ liệu lớn của bạn.
- Khi bạn có nhiều RAM :D
- Khi nghiệp vụ tính toán của bạn phức tạp.
Còn đối với dữ liệu chỉ có vài GB hay nghiệp vụ đơn giản ví dụ như đếm số dòng hay đếm số user thì tôi khuyên bạn không nên dùng vì nó phức tạp không cần thiết mà khéo khi lại còn chậm. Thay vào đó, khi bạn xử lý dữ liệu nhỏ hay tầm trung thì t khuyên bạn nên sử dụng AWK.
#3. AWK
3.1. Giới thiệu
Awk là một ngôn ngữ lập trình hỗ trợ thao tác dễ dàng đối với kiểu dữ liệu có cấu trúc và tạo ra những kết quả được định dạng. Nó được đặt tên bằng cách viết tắt các chữ cái đầu tiên của các tác giả: Aho, Weinberger và Kernighan.
AWK được tính hợp sẵn trong các hệ điều hành unix và linux nên chúng ta không cần cài đặt mà vẫn sử dụng bình thường. Rất tiện lợi phải không nào.
3.2. Khi nào nên sử dùng
Đơn giản thôi khi dữ liệu < vài chục GB và nghiệp vụ của bạn không quá phức tạp.
Vd: Bạn có file
id1|abc
id2|cdx
.............
Bạn cần đếm xem trong file
more
Chỉ sau vài giây hoặc ít hơn bạn đã có kết quả thay vì bạn cài đặt spark và rồi viết một câu spark sql dài ngoằng rồi đợi load file rồi đợi tính toán rồi đợi collect dữ liệu (nếu bạn muốn kết quả là một dạng số - hay biến nguyên thủy thay vì dạng RDD).
Đó chỉ cần bạn có chút kiến thức về vài dòng lệnh shell cơ bản là bạn đã có thể xử lý file dung lượng nhỏ rất nhanh rồi cần gì một framework to đâu :D

Một chút kinh dị khi bạn dùng AWK để xử lý nghiệp vụ phức tạp :D à mà thực ra thì nó có thể format sang dạng đẹp hơn :D
Còn nếu bạn vẫn thích hay quen "hard core" hay nghiệp vụ của bạn cũng khá phức tạp thì bạn có tham khảo Pandas
#4. Pandas
4.1. Giới thiệu
Về cơ bản thì Pandas có cách code khá giống với Spark. Bạn nào quen dùng Spark thì dùng Pandas cũng thế dễ dàng hơn.
Về tổ chức dữ liệu thì Padas sẽ query của gần như sql và dữ liệu được tổ chức thành dạng bảng với tên gọi là data frame.
4.2. Khi nào nên dùng
- Khi file bạn ở tầm trung trở xuống.
- Số bản ghi không quá nhiều.
- Nghiệp vụ phức tạp.
- Không cần xử lý song song và phân tán.
- Khi server bạn khỏe :D
Trên đây là 4 công cụ tôi hay dùng để xử lý dữ liệu. Tùy vào độ lớn, sự phức tạp của bài toán mà tôi chọn lấy một công cụ xử lý. À tất nhiên ngoài 4 công cụ này ra thì còn nhiều nữa nhưng tạm thời dừng ở những thứ phổ biến này thôi. Tôi hi vọng bài viết này sẽ giúp cho các bạn chọn lựa được công cụ phù hợp với bài toán của mình tránh tình trạng dùng dao mổ trâu để giết gà như tôi đã từng mắc phải :D
1s quảng cáo

big data
,data processing
,data scientist
,data mining
,công nghệ thông tin
Cảm ơn bài viết của bạn!
Đào Anh Quân
Cảm ơn bài viết của bạn!