Trí tuệ nhân tạo (AI) là gì? (Phần 1)
Trí tuệ nhân tạo là gì (AI)?
Vào những năm 1950, cha đẻ của lĩnh vực này Minsky và McCarthy, mô tả trí tuệ nhân tạo là bất kỳ tác vụ nào thực hiện bởi một chương trình hay máy móc mà nếu con người muốn thực hiện tác vụ này phải sử dụng đến trí tuệ để hoàn thành.
Đây hiển nhiên là một định nghĩa khá rộng, nó làm chúng ta đôi khi sẽ thấy các tranh luận cái gì là AI thực sự và cái gì không là AI.
Các hệ thống AI thông thường sẽ tập trung tối thiểu vào một số các hành vi liên quan đến trí tuệ của con người như sau: lập kế hoạch, học tập, lý luận, giải quyết vấn đề, trình bày kiến thức, nhận thức, chuyển động và thao tác, và ở mức độ thấp hơn là trí thông minh xã hội và sáng tạo.
Những cái gì đang sử dụng AI?
AI có mặt khắp nơi ngày nay, được sử dụng để gợi ý những gì bạn mua hàng, hiểu những gì bạn nói với các trợ lý ảo như Alexa của Amazon hay Apple Siri, để nhận ra ai và cái gì trong ảnh, để nhận ra spam hoặc phát hiện gian lận thẻ tín dụng.
Có những loại AI nào?
AI với cách chia cơ bản nhất có thể chia thành 2 dạng lớn: AI hẹp (Narrow AI) và AI phổ thông (General AI).
AI hẹp là những gì chúng ta có thể thấy quanh chúng ta ngày nay: Các hệ thống thông tin có thể dạy được hay học được để biết làm như nào có thể thực hiện được những tác vụ cụ thể mà không cần được lập trình rõ ràng làm thế nào để làm như vậy.
Các dạng trí tuệ máy này có thể thấy rõ ràng như việc nhận dạng ngôn ngữ và tiếng nói trong trợ lý ảo Siri trên Apple iPhone, trong các hệ thống thị giác máy của các loại xe tự hành, trong các công cụ gợi ý đề xuất các sản phẩm bạn có thể sẽ thích dựa trên dữ liệu từ những gì bạn mua trước đây. Không giống như con người, những hệ thống chỉ có thể học hay được dạy để thực hiện các tác vụ cụ thể, đấy là lý do tại sao chúng được gọi là AI hẹp.
Những gì AI hẹp có thể làm được?
Có rất nhiều ứng dụng mới hiện nay sử dụng AI hẹp: diễn giải các dữ liệu video từ máy bay không người lái thực hiện kiểm tra các cơ sở hạ tầng như đường ống dẫn dầu, tổ chức lịch cá nhân và công việc, trả lời các yêu cầu dịch vụ khách hàng đơn giản, phối hợp với các hệ thống thông minh khác để thực hiện các nhiệm vụ như đặt phòng khách sạn vào thời điểm và vị trí thích hợp, giúp các bác sĩ phát hiện các khối u tiềm tàng trong ảnh chụp X-quang, gắn cờ đối với nội dung trực tuyến không phù hợp, phát hiện hao mòn trong hệ thống thang máy từ dữ liệu được thu thập bởi các thiết bị IoT, ….
Những gì AI phổ thông có thể làm được?
AI phổ thông là thứ rất khác AI hẹp và gần với những gì được thấy ở con người, trí tuệ nhân tạo này có thể thực hiện rất nhiều các tác vụ khác nhau, tất cả mọi thứ từ việc đơn giản như cắt tóc cho đến việc xây dựng các bảng tính phức tạp, hoặc có thể suy luận nhiều chủ đề rộng dựa trên kinh nghiệm tích lũy được của nó. Dạng AI này các bạn có thể thấy trên phim ảnh, như HAL trong 2001 hay Skynet trong The Terminator, tuy nhiên nó chưa tồn tại thực tế ngày nay và các chuyên gia về AI vẫn còn bị chia rẽ về quan điểm bao lâu nữa nó có thể trở thành thực tế.
Một cuộc khảo sát giữa 4 nhóm chuyên gia trong năm 2012/2013 bởi nhà nghiên cứu AI Vincent C Müller và nhà triết học Nick Bostrom cho rằng có khoảng 50% khả năng AI phổ thông (Artificial General Intelligence – AGI) có thể được phát triển thành công vào giữa những năm 2040 và 2050, và xác suất thành công lên đến 90% vào năm 2075. Nhóm này thậm chí đi xa hơn, dự đoán về “siêu trí tuệ nhân tạo”, được định nghĩa là “bất kỳ dạng trí tuệ nào vượt quá khả năng nhận thức của con người trong toàn bộ các lĩnh vực liên quan” – được dự đoán có thể thành hiện thực 30 năm sau khi hoàn thành AGI.
Một số chuyên gia AI tin rằng những dự đoán như vậy là quá lạc quan do sự hiểu biết hạn chế của chúng ta về bộ não con người và tin rằng AGI vẫn còn cách xa thực tại hàng thế kỷ.
Học máy (machine learning) là gì?
Đây là một lĩnh vực lớn trong nghiên cứu về AI, và hiện đang được sử dụng lại mạnh mẽ, học máy là kỹ thuật mà hệ thống máy tính được cung cấp một lượng lớn dữ liệu, sau đó nó có thể học để thực hiện một nhiệm vụ cụ thể, chẳng hạn như hiểu được tiếng nói hay chú thích cho một bức ảnh.
Mạng Nơ-ron là gì?
Quá trình chính của học máy là mạng nơ-ron. Đây là mạng lưới lấy cảm hứng từ bộ não với các tầng thuật toán có tính liên kết với nhau, gọi là nơ-ron, các tầng này cung cấp dữ liệu lẫn cho nhau, và được dạy để thực hiện những tác vụ cụ thể bằng cách thay đổi các tham số quan trọng đến dữ liệu đầu vào khi nó đi qua các tầng. Trong suốt quá trình dạy của mạng nơ-ron, các trọng số được gán với các đầu vào khác nhau sẽ tiếp tục thay đổi cho đến tận khi đầu ra của mạng nơ-ron rất gần với cái mong muốn, tại thời điểm đó mạng sẽ “học” được cách thực hiện một tác vụ cụ thể.
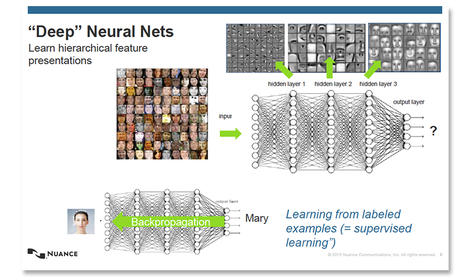
Học sâu (Deep Learning) là một tập con của học máy, nơi các mạng nơ-ron được mở rộng thành những mạng cực lớn với lượng lớn các tầng được dạy với lượng dữ liệu khổng lồ. Chính mạng lưới học sâu này đã thúc đẩy khả năng của máy tính trong việc thực hiện nhận dạng giọng nói hay thị giác máy.
Có nhiều loại mạng nơ-ron, với các điểm mạnh và điểm yếu khác nhau. Các mạng nơ-ron hồi quy (Recurrent Neural Network) là một dạng mạng nơ-ron đặc biệt phù hợp với việc xử lý ngôn ngữ và nhận dạng tiếng nói, trong khi đó mạng nơ-ron tích chập (Convolutional Neural Network) thường được sử dụng đối với các bài toán nhận dạng hình ảnh. Thiết kế của các mạng nơ-ron hiện cũng đang phát triển, các nhà nghiên cứu hiện tại đang tinh chỉnh hiệu quả của một dạng mạng nơ-ron học sâu được gọi là mạng LSTM (long short-term memory) với khả năng thực hiện đủ nhanh để sử dụng trong các hệ thống phản hồi theo yêu cầu (on-demand system) như Google Translate.
Một lĩnh vực khác của nghiên cứu AI là phép tính toán tiến hóa (evolutionary computation), vay mượn từ lý thuyết chọn lọc tự nhiên nổi tiếng của Darwin, các thuật toán di truyền (genetic algorithms) trải qua các đột biến và kết hợp ngẫu nhiên giữa các thế hệ khi cố gắng đưa ra giải pháp tối ưu cho một vấn đề nhất định.
Cách tiếp cận này được sử dụng để hỗ trợ thiết kế các mô hình AI, hiệu quả trong việc sử dụng chính AI để giúp xây dựng AI. Nó sử dụng các giải thuật tiến hóa (evolutionary algorithms) để tối ưu các mạng nơ-ron được gọi là neuro-evolution, và có thể có vai trò quan trọng trong việc giúp thiết kế AI hiệu quả khi mà việc sử dụng các hệ thống thông minh trở lên phổ biến trong khi nguồn cung nhân lực data scientist là có giới hạn. Kỹ thuật này được sử dụng trong trường hợp của Uber AI Lab, đã công bố một bài báo về việc sử dụng thuật toán di truyền để dạy mạng nơ-ron học sâu cho vấn đề học củng cố.
Cuối cùng là các hệ thống chuyên gia (expert system), là các chương trình được lập trình cho phép chúng có thể đưa ra một loạt các quyết định dựa trên số lượng lớn các đầu vào, cho phép máy móc có thể bắt chước hành vi của một chuyên gia trong một lĩnh vực cụ thể. Một ví dụ về các hệ thống dựa trên tri thức này có thể là, ví dụ, hệ thống lái tự động lái máy bay.
Điều gì đang thúc đẩy sự hồi sinh của AI?
Những đột phá lớn nhất trong nghiên cứu AI những năm gần đây là trong lĩnh vực học máy, đặc biệt là trong lĩnh vực học sâu.
Lĩnh vực này được thúc đẩy bởi sự sẵn có của dữ liệu, và thậm chí còn nhiều hơn bởi sự bùng nổ về sức mạnh tính toán song song trong những năm gần đây, với việc sử dụng các cụm GPU để dạy các hệ thống học máy trở nên phổ biến hơn.
Các cụm GPU không chỉ cung cấp các hệ thống mạnh hơn rất nhiều để dạy các mô hình học máy, mà giờ đây chúng còn phổ biến với các dịch vụ đám mây qua internet. Theo thời gian, các công ty công nghệ lớn, như Google và Microsoft, đã chuyển sang sử dụng các chip chuyên dụng phù hợp cho cả việc chạy và gần đây là để dạy các mô hình học máy.
Một trong những ví dụ của chip được tùy biến là TPU - Google's Tensor Processing Unit, phiên bản mới nhất giúp tăng tốc độ các mô hình học máy hữu ích được xây dựng bằng thư viện phần mềm TensorFlow của Google có thể suy luận ra thông tin từ dữ liệu, cũng như tốc độ được dạy.
Những chip này không chỉ sử dụng để dạy cho mô hình DeepMind và Google Brain, nó còn sử dụng để làm nền tảng cho Google Translate và nhận dạng hình ảnh trong Google Photo, cũng như cho phép người dùng xây dựng các mô hình học máy sử dụng Google's TensorFlow Research Cloud. Thế hệ thứ 2 của loại chip này vừa được công bố năm ngoái tại hội nghị Google's I/O, với tốc độ dạy mô hình học máy nhanh gấp đôi so với một GPU hàng đầu hiện nay.
(Còn nữa)
Theo www.zdnet.com