Tổng quan về nhận dạng tiếng nói
Trong phần này mình sẽ trình bày những kiến thức hết sức cơ bản về một hệ thống nhận dạng tiếng nói một cách dễ hiểu nhất, hạn chế sử dụng những công thức phức tạp để giúp các bạn chưa có điều kiện học tập, nghiên cứu về lĩnh vực này có cái nhìn tổng quan nhất về nhận dạng tiếng nói. Về phần tổng hợp tiếng nói (Text to Speech) các bạn có thể tham khảo tài liệu của bạn Nguyễn Văn Thịnh được viết rất chi tiết tại

Nếu các bạn muốn tìm hiểu chi tiết hơn có thể xem thêm một số tài liệu bằng tiếng Anh.
[1] Do Van Hai, “Acoustic modeling for speech recognition under limited training data conditions,” PhD Thesis, Nanyang Technological University, 2015,

[2] Quoc Bao Nguyen, Van Hai Do, Ba Quyen Dam, Minh Hung Le, “Development of a Vietnamese Speech Recognition System for Viettel Call Center,” in Proceedings of Oriental COCOSDA, pp. 104-108, 2017.

Ngoài ra các bạn có thể trải nghiệm hệ thống nhận dạng tiếng nói của VTCC tại
Sau đây mình sẽ trình bày về nhận dạng tiếng nói (Automatic Speech Recognition- ASR) hay còn gọi là chuyển đổi từ tiếng nói sang văn bản (Speech to Text).
Như mô tả trên Hình 1, một hệ thống nhận dạng tiếng nói gồm 5 thành phần chính. Chúng ta sẽ tìm hiểu chức năng và ý nghĩa của từng thành phần ngay sau đây.
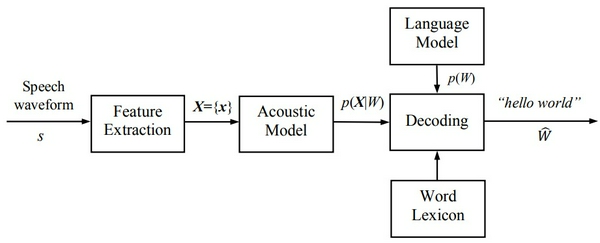
Hình 1. Một Hệ thống nhận dạng tiếng nói điển hình.
1. Trích chọn đặc trưng (Feature Extraction)
Module này có nhiệm vụ trích xuất ra những thông tin có ích và loại bỏ những thông tin dư thừa (ví dụ nhiễu). Do tiếng nói là liên tục, các đặc trưng được trích xuất dưới dạng các frame. Thông thường mỗi frame có độ rộng 25ms và các frame cách nhau 10ms vì người ta đã nghiên cứu rằng trong khoảng 25ms thì các đặc tính của tiếng nói được cho là ổn định. Với mỗi một frame ta sẽ trích chọn ra một vector đặc trưng, thông dụng nhất là MFCC (Mel filterbank cepstral coefficients). Với cách trích chọn đặc nhưng như thế này ta có thể thấy rằng dữ liệu cho nhận dạng tiếng nói là rất lớn. Ví dụ 1 giờ dữ liệu sẽ có 360.000 vector đặc trưng. Một hệ thống nhận dạng tiếng nói thương mại có thể cần đến 10.000 giờ dữ liệu tức 3,6 tỷ vector. Do vậy để train (huấn luyện) các hệ thống nhận dạng tiếng nói lớn, ta cần các máy tính tốc độ cao, có khả năng tính toán và lưu trữ rất lớn.
Một số vấn đề cần tìm hiểu:
- Các đặc trưng cho ngôn ngữ có thanh điệu như tiếng Việt.
- Các đặc trưng ổn định với nhiễu.
- Các đặc trưng được huấn luyện trước.
2. Mô hình âm học (Acoustic Model)
Module thứ 2 đó mà mô hình âm học. Nó hoạt động giống như tai người, đầu vào là đặc trưng của tiếng nói, X, đầu ra là xác suất có điều kiện của từ (word) hay âm vị (phoneme), P(X|W). Các tham số của mô hình âm học được xác định thông qua quá trình huấn luyện trên tập mẫu có trước. Mô hình xác suất được sử dụng phổ biến cho mô hình âm học là mô hình Markov ẩn (HMM - Hidden Markov Model) bởi mô hình này cung cấp một khung mô hình đơn giản và hiệu quả để mô hình hóa chuỗi vector theo thời gian. Để mô tả phân bố xác suất của các đặc trưng đầu vào về không gian người ta thường dùng mô hình Gaussian Mixture Model (GMM) hoặc mạng nơ ron (Neural Network). Trong đó mạng nơ ron, đặc biệt là mạng nơ ron sâu (Deep Neural Network) được sử dụng rộng rãi hiện nay đã tạo một bước đột phá trong nhận dạng tiếng nói.
Một số vấn đề cần tìm hiểu khi xây dựng mô hình âm học:
- Xây dựng mô hình ổn định trong môi trường nhiễu, nhiều tạp âm.
- Mô hình hóa được giọng vùng miền khác nhau.
- Mô hình hóa được các kênh truyền khác nhau.
3. Mô hình ngôn ngữ (Language Model)
Trong khi mô hình âm học mô phỏng tai người thì mô hình ngôn ngữ mô tả não người :). Mô hình ngôn ngữ lưu trữ những những tri thức (prior knowledge) về từ ngữ, về ngữ pháp, nói chung là những thông tin liên quan đến knowledge của một ngôn ngữ. Những kiến thức này được thay đổi liên tục theo thời gian. Do đó, mô hình ngôn ngữ cần được update thường xuyên. Ví dụ khi chúng ta nghe tiếng Anh, đôi khi chúng ta không nghe rõ từ (acoustic model yếu) nhưng chúng ta vẫn đoán được gần như chính xác từ ta không nghe được. Đó là do language model dựa vào những thông tin trước đó như về ngữ pháp đã giúp chúng ta đoán được. Hoặc ở ví dụ này, mô hình âm học khó có thể phân biệt 2 câu dưới đây do cách phát âm rất giống nhau.
1. “He likes ice cold drinks”
2. “He likes eyes cold drinks”.
Tuy nhiên ta không cần nghe cũng biết là câu thứ nhất đúng, đó là do mô hình ngôn ngữ.
Mô hình ngôn ngữ đơn giản và phổ biến hiện nay là mô hình n-gram. Trong mô hình này, xác suất của từ thứ n được xác định dựa trên (n-1) từ đứng trước nó P(Wn|Wn-1...W1). N thường bằng 3 hoặc 4 cho các hệ thống nhận dạng tiếng nói hiện nay. Mô hình ngôn ngữ n-gram tuy đơn giản nhưng cũng có nhược điểm là không mô tả được sự phụ thuộc dài do giới hạn của n. Hiện nay có một hướng nghiên cứu là sử dụng mạng nơ ron hồi quy (RNN) để mô tả mô hình ngôn ngữ.
Một số vấn đề cần tìm hiểu:
- Xây dựng mô hình ngôn ngữ cho các domain khác nhau.
- Xây dựng mô hình ngôn ngữ cho các domain có ít dữ liệu.
4. Từ điển phát âm (lexicon hay pronunciation dictionary)
Mô hình âm học thường dùng để mô hình hóa những phần từ nhỏ nhất của tiếng nói gọi là âm vị (phoneme). Trong khi đó, mô hình ngôn ngữ lại thường sử dụng từ (word) để mô hình hóa. Do vậy cần có một cầu nối giữa hai mô hình này đó là lexicon. Lexicon mô tả cách phát âm của 1 từ bằng cách biểu diễn từ đó dưới dạng một chuỗi các phonemes.
Một số vấn đề cần tìm hiểu:
- Một từ có nhiều cách phát âm.
- Cách phát âm những từ nước ngoài, viết tắt.
- Cách phát âm khác nhau giữa các vùng miền.
- Các từ không có trong từ điển - OOV (Out-Of-Vocabulary).
5. Giải mã (decoding)
Mỗi mỗi tín hiệu tiếng nói đầu vào, X, mô hình âm học sẽ đưa ra xác suất (ta có thể gọi là acoustic score), P(X|W) cho mỗi giả thuyết khác nhau về chuỗi text có thể đúng, W. Mô hình ngôn ngữ cũng đưa ra xác suất của mình (language score) cho giả thuyết W là P(W). Bộ giải mã (decoder) sẽ duyệt tất cả những chuỗi text (giả thuyết) có thể đúng, W, lấy P(X|W) từ mô hình âm học và P(W) từ mô hình ngôn ngữ để chọn ra chuỗi W có xác suất P(W|X) lớn nhất làm kết quả nhận dạng.
P(W|X) có thể được tính bằng công thức Bayes
P(W|X)=P(X|W)P(W)/P(X).
Do P(X) là không đổi với các giả thuyết W khác nhau ta có thể bỏ qua yếu tố này khi giải mã.
Chú ý rằng trong các bài toán nhận dạng tiếng nói số lượng từ vựng thường hàng nghìn hoặc hàng chục nghìn từ, số lượng từ trong chuỗi text W cũng chưa biết trước. Do vậy không gian tìm kiếm là rất lớn. Vì vậy việc giải mã trong nhận dạng tiếng nói của các hệ thống nhận dạng từ vựng lớn, liên tục thường rất tốn tài nguyên và thường thực hiện trên phía server.
Một số vấn đề cần tìm hiểu:
- Cách thức tăng tốc độ giải mã, tối ưu hóa tài nguyên.
- Giải mã thời gian thực.
Trên đây là những kiến thức hết sức cơ bản về nhận dạng tiếng nói và những vấn đề cần tiếp tục tìm hiểu, nghiên cứu. Nếu các bạn có thắc mắc xin vui lòng đặt câu hỏi tại:
