Toàn bộ về mạng GRU
Trong bài viết này, tôi sẽ cố gắng để đưa ra cho các bạn một lời giài thích đơn giản và dễ hiểu nhất về mạng nơ-ron thực sự hấp dẫn có tên GRU (Gated Recurrent Unit). Được giới thiệu bởi
GRU hoạt động thế nào?
Như đã đề cập ở trên, GRU là phiên bản cải thiện của mạng RNN truyển thống. Nhưng điều gì khiến nó đặc biệt và thực sự hiệu quả?
Để giải quyết vấn đề mất mát gradient của mạng RNN truyền thống, GRU đã được sử dụng và gọi là cổng cập nhật và cổng cài đặt lại (update gate và reset gate). Về cơ bản, đó chính là hai vector quyết định thông tin nào sẽ được truyền cho đầu ra. Điều đặc biệt là nó có thể được đào tạo để giữ thông tin từ lâu trước đó, không hề xóa thông tin không liên quan đến dự đoán đầu ra.
Để giải thích toán học đằng sau quá trình đó, tôi sẽ trình bày cho các bạn về mô hình của GRU như sau:
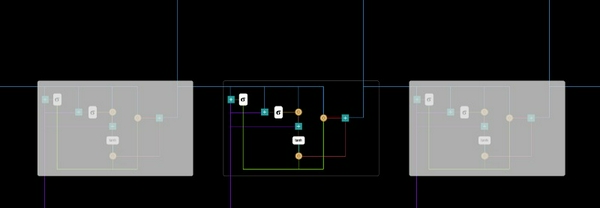
Recurrent neural network with Gated Recurrent Unit
Dưới đây là phiên bản chi tiết cho một GRU đơn lẻ:
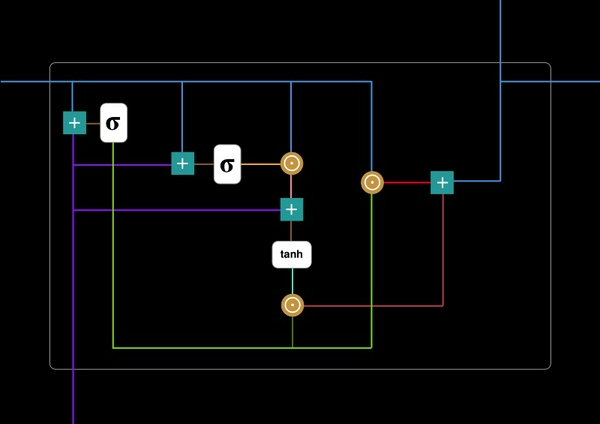
Gated Recurrent Unit
Đầu tiên, hãy để tôi giới thiệu về những ký hiệu toán học:

Nếu như bạn không hiểu về những thuật ngữ nói trên, tôi khuyên bạn nên đọc qua những hướng dẫn về chúng
#1. Update gate (cổng cập nhật)
Tôi sẽ bắt đầu bằng cổng cập nhật z_t tại thời gian t bằng cách sử dụng công thức sau:

Khi x_t được đưa vào mạng, nó được nhân với trọng lượng W(z) của nó.. Chúng như vậy với h_(t-1) chứa thông tin của các đơn vị tại thời điểm t-1 trước đó và nhân với trọng lượng riêng của nó U(z). Cả hai kết quả được cộng với nhau và qua hàm sigmoid để nén kết quả trong khoảng [0,1]. Dưới đây là lược đồ mô tả hoạt động của cổng này:
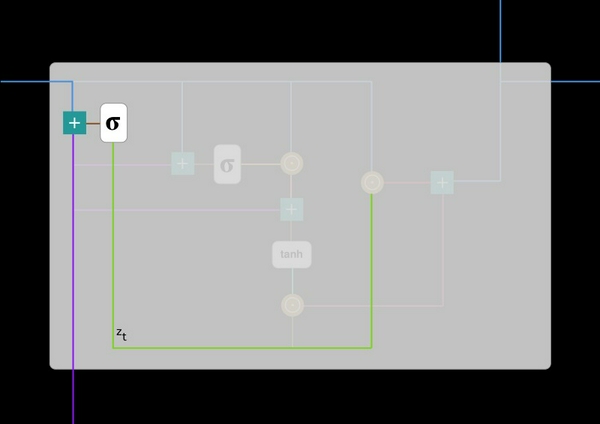
Cổng cập nhật giúp mô hình xác định được lượng thông tin trong quá khứ (thông tin ở bước t-1) cần chuyển đến tương lai (bước t). Điều này thực sự hữu ích bởi vì mô hình có thể quyết định copy tất cả thông tin từ quá khứ và loại bỏ nguy cơ mất mát gradient. Chúng ta sẽ thấy việc sử dụng cồng cập nhật ở bên dưới. Bây giờ việc của bạn chỉ là nhớ công thức z_t.
#2.Reset gate(Cổng cài đặt lại).
Về cơ bản, cổng này được sử dụng từ mô hình để quyết định lượng thông tin trong quá khứ bị quyên đi. Và được tính toán bởi công thức:
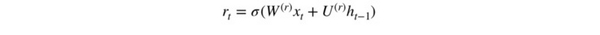
Công thức này giống như là công thức ở cổng update đã nêu trên. Sự khác biệt chỉ là ở trọng lượng và mức sử dụng của cổng này. Điều này lát nữa các bạn sẽ được thấy. Lược đồ dưới đây là hình ảnh nơi đặt cổng reset:
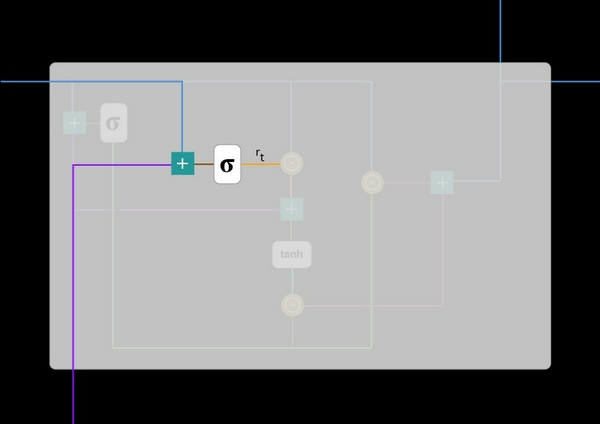
#3. Current memory content (Nội dung nhớ hiện tại)
Hãy xem chính xác các cổng nói trên có ảnh hưởng thế nào đến kết quả đầu ra nhé. Đầu tiên, tôi sẽ sử dụng cổng reset. Dưới đây là thông tin nội dung của bộ nhớ mới sẽ sử dụng cổng reset để lưu trữ thông tin có liên quan đến quá khứ:
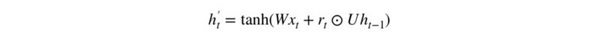
Các bước thực hiện của công thức trên:
- Phép nhân x_t với trọng số W và h_(t-1) với trọng số U.
- Phép nhân chập giữa cổng reset r_t và Uh_(t-1). Phép nhân chập sẽ xác định xem những gì cần phải xóa khỏi ở thời điểm trước đó.
- Cộng kết quả ở bước 1 và 2
- Sử dụng hàm tanh.
Hãy xem lược đồ dưới đây để hiểu hơn nhé:
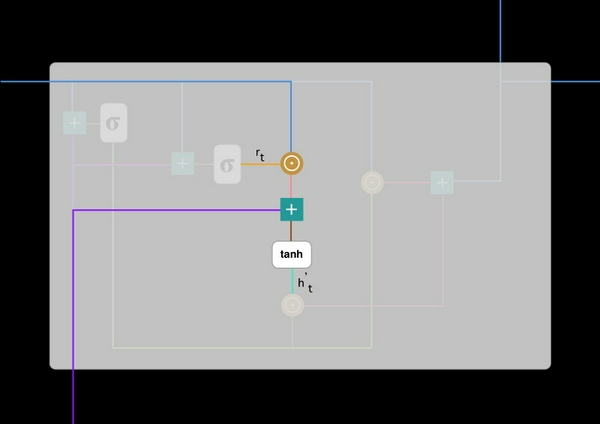
#4. Final memory at current time step (bộ nhớ tại thời điểm hiện tại)
Ở bước cuối cùng, đầu ra của mạng là cần tính h_t - vector chứa toàn bộ thông tin ở tại thời điểm t và truyền nó đi. Để thực hiện điều này, cần có cổng update. Nó xác định nội dung thu thập từ bộ nhớ hiện tại - h'_t và những gì từ các bước trước đó h_(t-1):
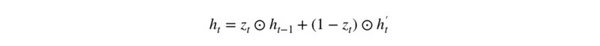
Các bước thực hiện như sau:
- Nhân chập từ cổng update z_t và h_(t-1)
- Nhân chập (1-z_t) với h'_t.
- Thực hiện phép cộng với kết quả ở bước 1 và 2.
Dưới đây là lược đồ cho phương trình trên:
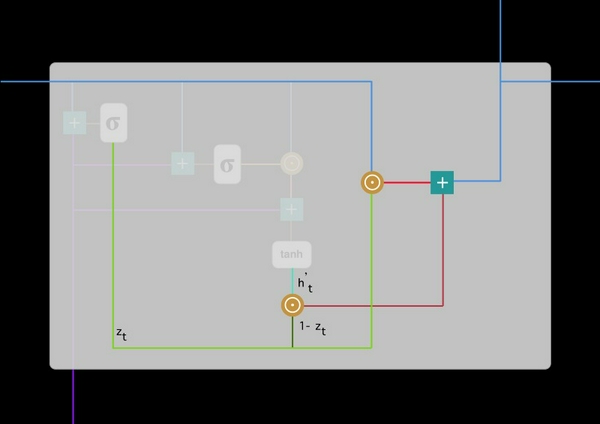
Giờ bạn đã hiểu cách mà GRU sử dụng cổng update và cổng reset rồi chứ. Điều này đã giúp loại bỏ các vấn đề biến mất gradient. Nếu được huấn luyện cẩn thận, nó có thể thực hiện rất tốt ngay cả trong những trường hợp phức tạp.
Tôi hi vọng rằng bài báo này sẽ giúp bạn hiểu được về mô hình mạng GRU.
Cảm ơn vì đã đọc bài viết của tôi!
Tham khảo: Understanding GRU work.