Pandas, một thư viện xử lý dữ liệu tuyệt vời cho các data scientist
Hôm nay tôi sẽ giới thiệu với các bạn về pandas, một thư viện xử lý dữ liệu rất mạnh trên Python, đặc biệt trong ngành khoa học dữ liệu. Điều đặc biệt ở pandas là nó là một tập hợp của rất nhiều các thư viện con ẩn trong nó, vì vậy pandas cung cấp rất nhiều tính năng hữu ích cho người sử dụng.
Pandas lưu trữ dữ liệu theo một cách khá giống với Excel, đó là sử dụng các bảng hay còn được gọi là DataFrame. Bắt đầu sử dụng pandas với câu lệnh:

Những chức năng cơ bản
Đọc dữ liệu từ file csv:

Pandas cung cấp các option trong việc đọc file csv như:

với
- sep: dấu phân cách giữa các điểm dữ liệu trên 1 dòng
- encoding: định dạng của file dữ liệu
- nrows: số lượng hàng sẽ đọc
- skiprows: những hàng sẽ bỏ qua khi đọc dữ liệu
Ngoài ra còn một số hàm để đọc dữ liệu như: read_excel(), read_clipboard(), read_sql()
Ghi dữ liệu

Rất đơn giản phải không. Ngoài ra còn một số hàm để ghi dữ liệu như: to_excel(), to_json(), to_pickle().
Xem các số liệu về dữ liệu
Xem số chiều của dữ liệu:

Xem các thống kê về dữ liệu:

In dữ liệu lên màn hình
In 3 hàng đầu tiên:

In hàng thứ 8:

In phần tử ở hàng 8 cột ‘column_1’:

In hàng 4 và hàng 5:

Các logical operations trong pandas
Pandas cung cấp việc truy xuất dữ liệu có điều kiện bằng các operator & (AND), ~ (NOT) và | (OR) như các ví dụ dưới đây. Mỗi logical operation cần phải nằm trong ngoặc ()

Thay vì dùng nhiều phép ~ (OR), ta có thể sử dụng hàm .isin()

Vẽ đồ thị
Pandas sử dụng trực tiếp package matplotlib chứa trong nó để thực hiện các thao tác vẽ đồ thị. Để vẽ đồ thị về giá trị số thực của một cột dữ liệu ta gọi hàm .plot() trên cột dữ liệu đó.

Để vẽ đồ thị phân phối giá trị (histogram), ta gọi hàm .hist()

Nếu bạn đang code trên Jupyter, chạy câu lệnh này trước khi thực hiện vẽ đồ thị

Cập nhật dữ liệu
Thay đổi giá trị phần tử tại hàng 8, cột ‘column_1’ bằng ‘english’

Thay đổi giá trị của nhiều hàng cùng lúc

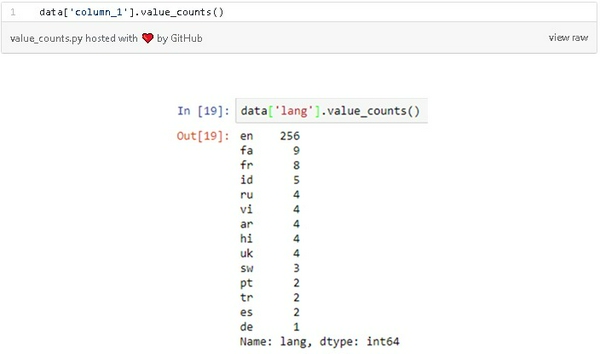
Thống kê số lần xuất hiện
Map và chain function trong pandas
Hàm .map() thực hiện việc gọi hàm được truyền vào tới từng phần tử của một cột. Ở ví dụ dưới đây làm len() sẽ được gọi trên tất cả các phần tử của cột ‘column_1’

Các hàm trong pandas có thể được gọi chồng lên nhau tạo thành 1 chain. Bạn hãy thử đoán xem câu lệnh dưới đây thực hiện chức năng gì nhé

Hàm .apply() thực hiện việc gọi hàm được truyền vào tới các cột dữ liệu. Câu lệnh dưới đây sẽ lấy tổng giá trị của từng cột

Package tqdm
Những operation trong pandas có thể sẽ tốt kha khá thời gian để thực hiện trên các tập dữ liệu lớn. Ta có thể theo dõi tiến trình thực hiện của các operation đó bằng cách sử dụng tqdm

Thay .map(), .apply() bằng progress_map() và progress.apply()

Ta có progress bar như dưới đây

Các hàm nâng cao trong pandas
SQL join
Ghép dữ liệu trong pandas trở nên đơn giản hơn rất nhiều bằng cách sử dụng hàm .merge(). Dưới đây là ví dụ về việc ghép 2 DataFrame có 3 cột chung

Grouping
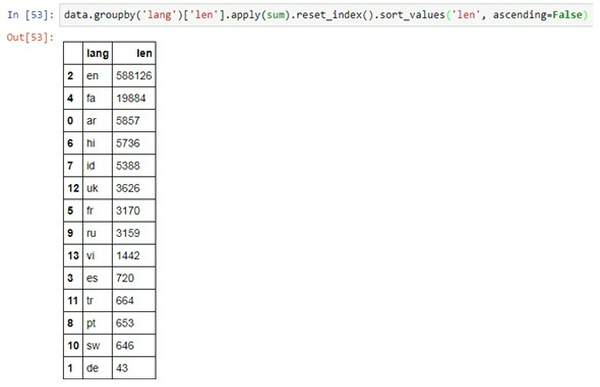
Ta có thể nhóm các cột lại với nhau bằng hàm .groupby(). Ở ví dụ dưới đây, ta nhóm dữ liệu theo cột ‘column_1’, sau đó lấy ra cột ‘column_2’ và áp dụng hàm .apply() lên cột này. Hàm .reset_index() có tác dụng biến đổi dữ liệu về dạng DataFrame

Loop với từng hàng
Hàm .iterrows() lặp qua các hàng của dữ liệu với 2 tham số i là số thứ tự của hàng và row là các phần tử tại hàng thứ i.

Kết
Pandas còn rất nhiều các chức năng tuyệt vời nữa nhưng chỉ qua các ví dụ ở trên, hẳn các bạn đã thấy tầm quan trọng của package này trong ngành khoa học dữ liệu rồi phải không. Sự tồn tại của những thư viện như Pandas chính là lý do mà Python được coi là một trong những ngôn ngữ lập trình mạnh mẽ nhất. Cảm ơn các bạn đã đọc và hẹn gặp lại :D
Nguồn: TowardsDataScience Be a more efficient data scientist, master pandas with this guide