One-hot: One-hot là gì? Tại sao và khi nào sử dụng nó?
Chắc chắn, khi làm việc với ML, bạn sẽ ít nhất một lần được nghe thấy cụm từ "one-hot encoding" hoặc "one-hot vector" (đấy là chưa kể có thể nghe thấy rất nhiều lần nữa).
Theo tài liệu của sklearn, one-hot là "Mã hóa các tính năng của một số nguyên sử dụng one-hot hay còn gọi là một chương trình one-hot". Thực sự lý thuyết này khá mông lung, tôi cảm giác nó không giành cho tôi. Hãy cùng tôi xem thực sự nó là gì?
One-hot encoding là một quá trình mà các biến phân loại (label) được chuyển đổi thành một mẫu có thể cung cấp cho các thuật toán ML để thực hiện công việc tốt hơn khi mà dự đoán.
Giả sử tôi có tập dữ liệu như sau:

categorycal value đại diện cho giá trị phân loại của bộ dữ liệu.
Bảng trên chỉ là biểu diễn dữ liệu, trên thực tế, giá trị phân loại bắt đầu từ 0 đến N-1.
Có thể một số bạn đã biết, cách gán giá trị phân loại có thể sử dụng thư viện sklean:
Tôi đã làm theo hướng dẫn như được đưa ra ở hướng dẫn ở sklearn. và tiền xử lý qua dữ liệu, tôi được bộ dữ liệu như sau:
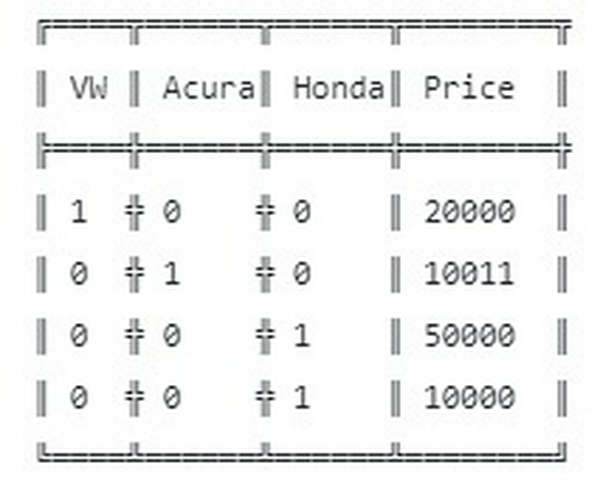
Trước khi tiếp tục, liệu bạn có thắc mắc rằng tại sao không dùng trực tiếp nhãn phân loại lại phải sử dụng đến one-hot? Tôi cũng từng ngồi nghĩ mãi như vậy, tại sao??
Hãy để tôi giải thích: Từ dữ liệu ban đầu, đặt VW = 1, Acura = 2, Honda = 3, từ số liệu ta nhận thấy3-1 = 2 chứng tỏ Acura=Honda-VW? wtf? Đây thực sự là công thức thảm họa. Chắc chắn sẽ rất nhiều lỗi.
Đây là lý do tại sao chúng ta sử dung one-hot encoding để thực hiện chuyển đổi nhãn và góp phần không nhỏ vào đào tạo mô hình.
Hi vọng rằng qua ví dụ và những gì mà tôi đã giải thích các bạn có thể hiểu được phần nào về one-hot. Cảm ơn các bạn đã theo dõi.
Tham khảo: What is One Hot Encoding? Why And When do you have to use it?