Machine Learning & ứng dụng trong những ngành công nghiệp lớn ra sao?
trí tuệ nhân tạo
Chào bạn, mình mong là sẽ giúp được bạn đôi chút:
Machine Learning là gì?
Có 2 định nghĩa khá rõ ràng về Machine Learning như sau:
- Theo Arthur Samuel (1959): Máy học là ngành học cung cấp cho máy tính khả năng học hỏi mà không cần được lập trình một cách rõ ràng
- Theo Giáo sư Tom Mitchell – Carnegie Mellon University: Machine Learning là 1 chương trình máy tính được nói là học hỏi từ kinh nghiệm E từ các tác vụ T và với độ đo hiệu suất P. Nếu hiệu suất của nó áp dụng trên tác vụ T và được đo lường bởi độ đo P tăng từ kinh nghiệm E
Ví dụ cho định nghĩa của Tom Mitchell
Giả sử như bạn muốn máy tính xác định một tin nhắn có phải là SPAM hay không
- Tác vụ T: Xác định 1 tin nhắn có phải SPAM hay không?
- Kinh nghiệm E: Xem lại những tin nhắn đánh dấu là SPAM xem có những đặc tính gì để có thể xác định nó là SPAM.
- Độ đo P: Là phần trăm số tin nhắn SPAM được phân loại đúng.
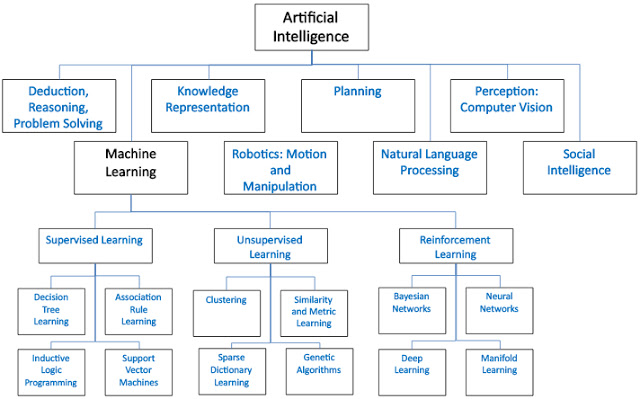
Một số methods machine learning nổi tiếng
Hai methods của Machine Learning được chấp nhận rộng rãi chính là supervised learning (học có giám sát) và unsupervised learning (học không giám sát) nhưng cũng có những methods khác như semisupervised learning (học bán giám sát), reinforcement learning (học tăng cường)
Dưới đây là khái niệm chung về 2 phương pháp phổ biến nhất:
Supervised Learning (SL) là một kĩ thuật học máy để học tập từ tập dữ liệu được gán nhãn cho trước. Tập dữ liệu cho trước sẽ chứa nhiều bộ dữ liệu. Mỗi bộ dữ liệu có cấu trúc theo cặp {x, y} với x được xem là dữ liệu thô (raw data) và y là nhãn của dữ liệu đó. Nhiệm vụ của SL là dự đoán đầu ra mong muốn dựa vào giá trị đầu vào. Dễ nhận ra, học có GIÁM SÁT tức là máy học dựa vào sự trợ giúp của con người, hay nói cách khác con người dạy cho máy học và giá trị đầu ra mong muốn được định trước bởi con người. Tập dữ liệu huấn luyện hoàn toàn được gán nhãn dựa vào con người. Tập càng nhỏ thì máy tính học càng ít.
SL cũng được áp dụng cho 2 nhóm bài toán chính là bài toán dự đoán (regression problem) và bài toán phân lớp (classification problem).
Kỹ thuật SL thực chất là để xây dựng một hàm có thể xuất ra giá trị đầu ra tương ứng với tập dữ liệu. Ta gọi hàm này là hàm h(x) và mong muốn hàm này xuất ra đúng giá trị y với một hoặc nhiều tập dữ liệu mới khác với dữ liệu được học. Hàm h(x) cần các loại tham số học khác nhau tùy thuộc với nhiều bài toán khác nhau. Việc học từ tập dữ liệu (training) cũng chính là tìm ra bộ tham số học cho hàm h(x).
Unsupervised learning (UL) là một kĩ thuật của máy học nhằm tìm ra một mô hình hay cấu trúc bị ẩn bởi tập dữ liệu KHÔNG được gán nhãn cho trước. UL khác với SL là không thể xác định trước output từ tập dữ liệu huấn luyện được. Tùy thuộc vào tập huấn luyện kết quả output sẽ khác nhau. Trái ngược với SL, tập dữ liệu huấn luyện của UL không do con người gán nhãn, máy tính sẽ phải tự học hoàn toàn. Có thể nói, học KHÔNG GIÁM SÁT thì giá trị đầu ra sẽ phụ thuộc vào thuật toán UL.
Ứng dụng: Ứng dụng phổ biến nhất của học không giám sát là gom cụm (cluster). Đương nhiên sẽ có nhiều ứng dụng khác, có cơ hội tôi sẽ đề cập thêm. Ứng dụng này dễ nhận ra nhất là Google và Facebook. Google có thể gom nhóm các bài báo có nội dung gần nhau, hoặc Facebook có thể gợi ý kết bạn có nhiều bạn chung cho bạn. Các bài báo có cùng nội dung sẽ được gom lại thành một nhóm (cluster) phân biệt với các nhóm khác. Dữ liệu huấn luyện là các bài báo từ quá khứ tới hiện tại và tăng dần theo thời gian. Dễ nhận ra rằng dữ liệu không thể gán nhãn bởi con người. Khi một bài báo mới được cho vào input, nó sẽ tìm cụm (cluster) gần nhất với bài báo đó và gợi ý những bài liên quan.
Phan Khắc Tài
Chào bạn, mình mong là sẽ giúp được bạn đôi chút:
Machine Learning là gì?
Có 2 định nghĩa khá rõ ràng về Machine Learning như sau:
Ví dụ cho định nghĩa của Tom Mitchell
Giả sử như bạn muốn máy tính xác định một tin nhắn có phải là SPAM hay không
Một số methods machine learning nổi tiếng
Hai methods của Machine Learning được chấp nhận rộng rãi chính là supervised learning (học có giám sát) và unsupervised learning (học không giám sát) nhưng cũng có những methods khác như semisupervised learning (học bán giám sát), reinforcement learning (học tăng cường)
Dưới đây là khái niệm chung về 2 phương pháp phổ biến nhất:
Supervised Learning (SL) là một kĩ thuật học máy để học tập từ tập dữ liệu được gán nhãn cho trước. Tập dữ liệu cho trước sẽ chứa nhiều bộ dữ liệu. Mỗi bộ dữ liệu có cấu trúc theo cặp {x, y} với x được xem là dữ liệu thô (raw data) và y là nhãn của dữ liệu đó. Nhiệm vụ của SL là dự đoán đầu ra mong muốn dựa vào giá trị đầu vào. Dễ nhận ra, học có GIÁM SÁT tức là máy học dựa vào sự trợ giúp của con người, hay nói cách khác con người dạy cho máy học và giá trị đầu ra mong muốn được định trước bởi con người. Tập dữ liệu huấn luyện hoàn toàn được gán nhãn dựa vào con người. Tập càng nhỏ thì máy tính học càng ít.
SL cũng được áp dụng cho 2 nhóm bài toán chính là bài toán dự đoán (regression problem) và bài toán phân lớp (classification problem).
Kỹ thuật SL thực chất là để xây dựng một hàm có thể xuất ra giá trị đầu ra tương ứng với tập dữ liệu. Ta gọi hàm này là hàm h(x) và mong muốn hàm này xuất ra đúng giá trị y với một hoặc nhiều tập dữ liệu mới khác với dữ liệu được học. Hàm h(x) cần các loại tham số học khác nhau tùy thuộc với nhiều bài toán khác nhau. Việc học từ tập dữ liệu (training) cũng chính là tìm ra bộ tham số học cho hàm h(x).
Unsupervised learning (UL) là một kĩ thuật của máy học nhằm tìm ra một mô hình hay cấu trúc bị ẩn bởi tập dữ liệu KHÔNG được gán nhãn cho trước. UL khác với SL là không thể xác định trước output từ tập dữ liệu huấn luyện được. Tùy thuộc vào tập huấn luyện kết quả output sẽ khác nhau. Trái ngược với SL, tập dữ liệu huấn luyện của UL không do con người gán nhãn, máy tính sẽ phải tự học hoàn toàn. Có thể nói, học KHÔNG GIÁM SÁT thì giá trị đầu ra sẽ phụ thuộc vào thuật toán UL.
Ứng dụng: Ứng dụng phổ biến nhất của học không giám sát là gom cụm (cluster). Đương nhiên sẽ có nhiều ứng dụng khác, có cơ hội tôi sẽ đề cập thêm. Ứng dụng này dễ nhận ra nhất là Google và Facebook. Google có thể gom nhóm các bài báo có nội dung gần nhau, hoặc Facebook có thể gợi ý kết bạn có nhiều bạn chung cho bạn. Các bài báo có cùng nội dung sẽ được gom lại thành một nhóm (cluster) phân biệt với các nhóm khác. Dữ liệu huấn luyện là các bài báo từ quá khứ tới hiện tại và tăng dần theo thời gian. Dễ nhận ra rằng dữ liệu không thể gán nhãn bởi con người. Khi một bài báo mới được cho vào input, nó sẽ tìm cụm (cluster) gần nhất với bài báo đó và gợi ý những bài liên quan.