Long tail distribution trong deep learning nghĩa là gì?
Mình chỉ biết nó là một task phân loại đặc biệt, còn có ý nghĩa sâu gì nữa ai đó giải thích giúp mình được không?
Mình xin cám ơn
deep learning
,trí tuệ nhân tạo
Hi bạn, đây là một câu hỏi rất thú vị! Cảm ơn vì đã chia sẻ!
Trước hết thì, khái niệm/mô hình long-tail distribution ("cái đuôi dài") xuất phát thực chất từ lĩnh vực kinh tế, được sử dụng đầu tiên bởi ông Chris Anderson - tổng biên tập tạp chí Wired.
Về cơ bản, mô hình này đi ngược lại tinh thần của quy tắc làm việc 80/20 (nếu ta biết khoanh vùng 20% những việc quan trọng nhất và tập trung thực hiện chúng, ta sẽ đạt được 80% hiệu suất làm việc). Với long-tail distribution, Chris cho rằng thực sự thì 80% công việc còn lại kia, nếu ta có thể giải quyết triệt để, thì vẫn sẽ mang lại hiệu suất cao không kém. (Điều này đặc biệt đúng trong nền kinh tế số hiện nay - cụ thể tại sao thì mình có thể giải thích sau, viết hết trong comment này sợ sẽ dài...).
Tuy nhiên, con người chúng ta ít ai có đủ kiên nhẫn hay sự chăm chỉ để có thể thực hiện 80% công việc có vẻ nhàm chán và ít quan trọng này. Đó là lý do long-tail distribution được đưa vào deep learning.
------------------------------
Oke, đó là khái niệm cơ bản. Ở đây mình sẽ đưa ra 1 ví dụ thế này, để các bạn hình dung rõ hơn ứng dụng cũng như tính cần thiết của mô hình này.
Hãy lấy ví dụ về công nghệ nhận diện khuôn mặt (face recognition tech), trong đó các AI học cách nhận diện các biểu cảm trên gương mặt của chúng ta qua việc thu thập và ghi nhớ thật nhiều ảnh với thật nhiều góc độ của thật nhiều người trên thế giới. Nguồn ảnh có thể đến từ Google, Facebook, Instagram...
Vấn đề là, không phải ai trong chúng ta cũng có sở thích chụp ảnh selfie và đăng tải lên Internet và MXH. Và thực sự thì, những người có nhiều hình ảnh trên Internet nhất, chính là các nguyên thủ quốc gia và người nổi tiếng trong giới showbiz. Họ chính là 20% những người sở hữu 80% hình ảnh trên Internet.
Trong khi đó, "dân đen" như chúng ta chiếm phần đông dân số (80%) và chỉ sở hữu 20% số hình mà các AI có thể tìm thấy và ghi nhớ. Việc này gây ra một vấn đề về việc "lấy mẫu" (sampling), bởi hình dạng khuôn mặt của 20% những người nổi tiếng kia không thể đại diện cho 80% phần còn của dân số được. Việc học tập của các AI, vì thế cũng sẽ gặp thiếu sót. Các bạn hãy quan sát biểu đồ dưới đây:
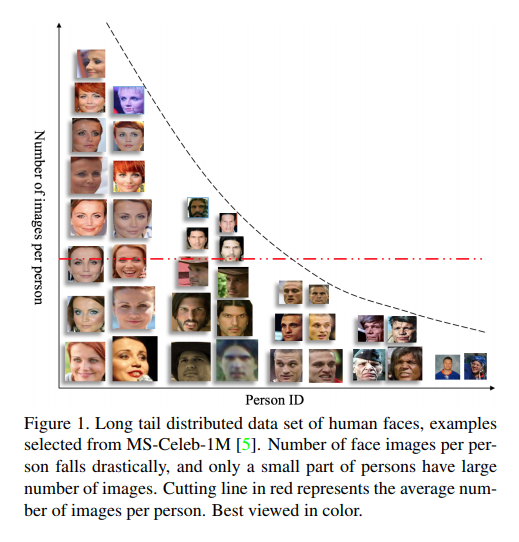
Trong biểu đồ trên, 20% những người nổi tiếng nằm về phía góc trái, và 80% các "dân đen" còn lại nằm về phía góc phải - chính là phần "long tail". Như vậy, ứng dụng của mô hình long-tail distribution trong deep learning chính là để giúp các AI không bỏ qua 80% dân số này, nhằm thu thập được một lượng hình ảnh khuôn mặt đầy đủ hơn.
Thân.
Woo Map
Hi bạn, đây là một câu hỏi rất thú vị! Cảm ơn vì đã chia sẻ!
Trước hết thì, khái niệm/mô hình long-tail distribution ("cái đuôi dài") xuất phát thực chất từ lĩnh vực kinh tế, được sử dụng đầu tiên bởi ông Chris Anderson - tổng biên tập tạp chí Wired.
Về cơ bản, mô hình này đi ngược lại tinh thần của quy tắc làm việc 80/20 (nếu ta biết khoanh vùng 20% những việc quan trọng nhất và tập trung thực hiện chúng, ta sẽ đạt được 80% hiệu suất làm việc). Với long-tail distribution, Chris cho rằng thực sự thì 80% công việc còn lại kia, nếu ta có thể giải quyết triệt để, thì vẫn sẽ mang lại hiệu suất cao không kém. (Điều này đặc biệt đúng trong nền kinh tế số hiện nay - cụ thể tại sao thì mình có thể giải thích sau, viết hết trong comment này sợ sẽ dài...).
Tuy nhiên, con người chúng ta ít ai có đủ kiên nhẫn hay sự chăm chỉ để có thể thực hiện 80% công việc có vẻ nhàm chán và ít quan trọng này. Đó là lý do long-tail distribution được đưa vào deep learning.
------------------------------
Oke, đó là khái niệm cơ bản. Ở đây mình sẽ đưa ra 1 ví dụ thế này, để các bạn hình dung rõ hơn ứng dụng cũng như tính cần thiết của mô hình này.
Hãy lấy ví dụ về công nghệ nhận diện khuôn mặt (face recognition tech), trong đó các AI học cách nhận diện các biểu cảm trên gương mặt của chúng ta qua việc thu thập và ghi nhớ thật nhiều ảnh với thật nhiều góc độ của thật nhiều người trên thế giới. Nguồn ảnh có thể đến từ Google, Facebook, Instagram...
Vấn đề là, không phải ai trong chúng ta cũng có sở thích chụp ảnh selfie và đăng tải lên Internet và MXH. Và thực sự thì, những người có nhiều hình ảnh trên Internet nhất, chính là các nguyên thủ quốc gia và người nổi tiếng trong giới showbiz. Họ chính là 20% những người sở hữu 80% hình ảnh trên Internet.
Trong khi đó, "dân đen" như chúng ta chiếm phần đông dân số (80%) và chỉ sở hữu 20% số hình mà các AI có thể tìm thấy và ghi nhớ. Việc này gây ra một vấn đề về việc "lấy mẫu" (sampling), bởi hình dạng khuôn mặt của 20% những người nổi tiếng kia không thể đại diện cho 80% phần còn của dân số được. Việc học tập của các AI, vì thế cũng sẽ gặp thiếu sót. Các bạn hãy quan sát biểu đồ dưới đây:
Trong biểu đồ trên, 20% những người nổi tiếng nằm về phía góc trái, và 80% các "dân đen" còn lại nằm về phía góc phải - chính là phần "long tail". Như vậy, ứng dụng của mô hình long-tail distribution trong deep learning chính là để giúp các AI không bỏ qua 80% dân số này, nhằm thu thập được một lượng hình ảnh khuôn mặt đầy đủ hơn.
Thân.
Người ẩn danh
Mình chưa hiểu rõ câu hỏi của bạn lắm.
Long tail distribution theo mình hiểu là một dạng phân phối trong các mô hình thống kê và mô hình nghiệp vụ mà tồn tại một lượng lớn tần suất xuất hiện xa ra khỏi phần "đầu".
Như hình dưới là một ví dụ:
Mình không nghĩ nó là một task phân loại vì ngay từ cái tên "distribution" dịch ra đã là "phân phối". Bạn có thể nói rõ hơn được không?
Người ẩn danh
Hi, mình là người hỏi câu hỏi này đây :D
Cám ơn bạn Woo Map và Người ẩn danh đã trả lời câu hỏi này của mình.
Mình có tìm đọc qua nghiên cứu và tạm thời hiểu nó như thế này.
Mình hiểu thì khi phân tích nhận dạng, ví dụ như trong training data (dữ liệu dùng để training), những loại ảnh bị cắt xén, hoặc ảnh không trực diện đối tượng cũng rất quan trọng mình không thể thấy nó bị cắt xén mà loại nó ra khỏi tập training data. Theo biểu đồ thì những ảnh thể hiện toàn diện được đối tượng sẽ có số lượng nhiều nhất (vì nó có nhiều pose, expression, ..) còn càng bị cắt nhiều lượng ảnh sẽ ít đi vì có ít thông tin có thể được thể hiện ra ảnh. Như theo sơ đồ bên dưới.
Cám ơn ví dụ của bạn Woo Map, đây cũng là một ví dụ rất đúng với kiểu long-tail distribution. :D
Còn về nó là task phân loại thì mình nghĩ đó là do nó phân loại ra thành từng kiểu ảnh khác nhau, mình hiểu thế này có đúng không nhỉ :-?