Làm thế nào để sử dụng word embedding layer cho Deep Learning (DL) sử dụng Keras.
Như ở bài trước, các bạn đã được biết đến Keras qua ví dụ nhỏ về phân loại text nhưng sử dụng bow. ở bài này, tôi sẽ giới thiệu qua cho các bạn về word embedding.
Word embedding biểu diễn một word dưới dạng một vector với số chiều thấp và phân bố dày đặc và ý nghĩa tương đối của nó. Nó cải tiến hơn so với những mô hình trước đó (những mô hình mà đa số có giá trị 0. Điều đặc biệt là word embedding có thể được training từ dữ liệu văn bản và tái sử dụng trong các dự án khác. Trong bài viết này, bạn sẽ khám phá cách sử dụng các word embedding vào DL trong Python bằng Keras.
Bạn sẽ nhận được gì từ bài viết này?
- Giới thiệu về word embedding và Embedding layer trong Keras.
- Làm thế nào để word embedding học được khi lắp vào mạng nơ-ron
- Làm thế nào để sử dụng một word embedding đã được đào tạo trước trong mạng nơ-ron
Tổng quan:
Trong bài viết này sẽ có 3 phần:
- Word Embedding
- Keras Embedding Layer
- Ví dụ về một Embedding
- Ví dụ về việc tái sử dụng một GloVe Embedding
- Word Embedding
Đây là một sự cải tiến so với mô hình bag-of-word truyền thống, trong đó các vector được biểu diễn dưới dạng khá thưa thớt (ta có thể hiểu vector thưa thớt gần giống như là một one-hot vector, khi đó vector đa số có giá trị bằng 0)
Thay vào đó, word embedding thì là một biểu diễn dày đặc (có thể hiểu rằng ngược lại hoàn toàn, số chiều của vector ít hơn, mà đặc biệt là cách biểu diễn của mỗi từ có sự gần gũi với nhau hơn). Khi chiếu lên không gian vector thì vị trí của các từ sẽ gần nhau hơn.. Hai ví dụ phổ biến mà bạn có thể tìm kiếm và tham khảo:
- Word2Vec
- GloVe
2. Keras Embedding Layer
Keras cung cấp một Embedding layer để sử dụng cho mạng nơ-ron trên tập dữ liệu văn bản.
Đầu vào yêu cầu là số nguyên được mã hóa, sao cho mỗi từ được biểu điễn bằng một số nguyên duy nhất. Bước chuẩn bị này có thể được thực hiện bằng cách sử dụng
Embedding layer được khởi tạo với trọng số (weight) ngẫu nhiên và sẽ tìm hiểu cách nhúng cho tất cả các từ trong tập dữ liệu training.
Nó là một layer khá linh hoạt và có thể sử dụng theo nhiều cách khác nhau, như sau:
- Nó có thể được sử dụng độc lập để học cách lưu một từ embedding và sử dụng trong model khác.
- Sử dụng như là một phần của model.
- Sử dụng để nhúng một model đã được train từ trước vào model mới.
Word Embedding là layer đầu tiên của mạng. Nó có 3 đối số đặc biệt như sau:
- input_dim: Kích thước của từ điển trong dữ liệu text đầu vào, nếu dữ liệu của bạn là số sang các giá trị từ 0-10 thì kích thước này là 11 từ.
- output_dim: Kích thước không gian vector mà từ sẽ được nhúng. Nó định nghĩa kích thước của vector đầu ra từ layer của mỗi word. Ví dụ 32 hoặc 100, nó tùy thuộc vào bài toán của bạn.
- input_length: Độ dài của chuỗi đầu vào. Ví dụ toàn bộ input của tôi có kích thước là 1000 thì trường này có giá trị 1000.
Dưới đây là ví dụ về Embedding layer có 200 vocabulary, vector có kích thước 32, và đầu vào mỗi câu có 50 từ:

3. Ví dụ
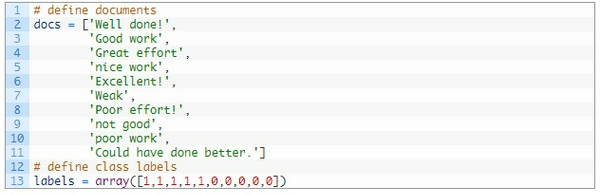
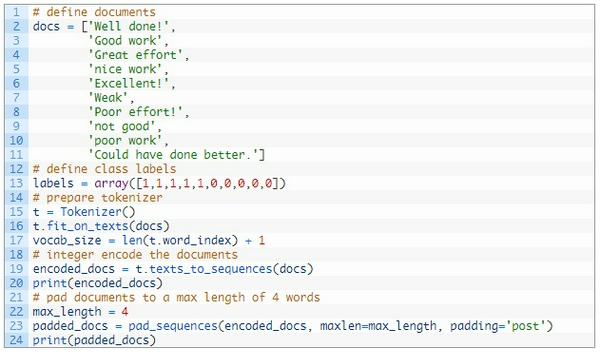
Dưới đây tôi sẽ ví dụ một bộ dữ liệu nhỏ gồm 10 câu văn, mỗi câu văn là nhận xét về một tác phẩm mà sinh viên đã gửi. Mỗi tài liệu sẽ được phân loại là 1 hoặc 0.
Đầu tiên tôi sẽ định nghĩa data của tôi thế này:
Tiếp theo ta sẽ thực hiện quá trình mã hóa cho 10 văn bản trên bằng số. Keras đã cung cấp hàm

Các đầu vào có thể khác nhau nhưng mà input đầu vào cần phải giống nhau, vì vậy tôi sẽ pad hết về kích thước dài nhất trong các câu input. Ở ví dụ này là 4, tôi sử dụng hàm pad_sequences():

Tiếp theo, tôi sẽ chọn một không gian nhỏ để embedding là 8, Mô hình phân loại nhị phân đơn giản.Quan trọng hơn, đầu ra từ lớp nhúng này sẽ là 4 vector với 8 chiều, Tôi sẽ làm phẳng nó thành một phần tử 32 lớp để truyền vào Dense.
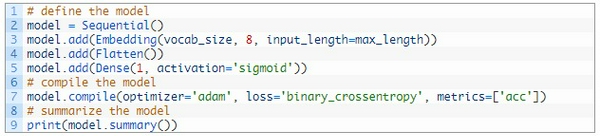
Cuối cùng thì tôi sẽ fit và đánh giá model:

Dưới đây là code hoàn chỉnh:
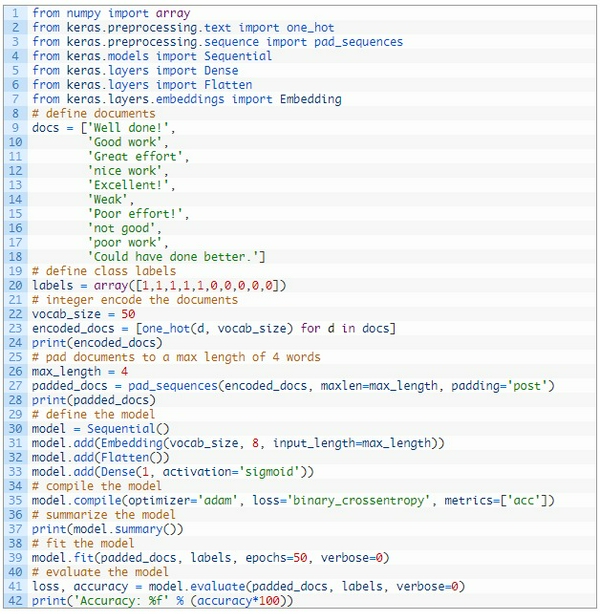
đây là mô hình mà tôi đã sử dụng:
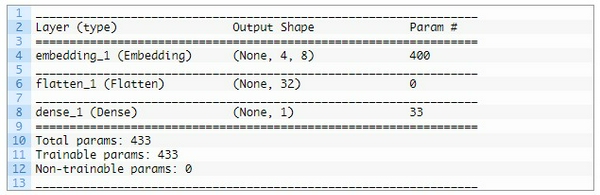
Kết quả tôi nhận được là Accuracy = 100%.
Bạn có thể lưu lại weights từ Embedding layer để dùng cho model khác.
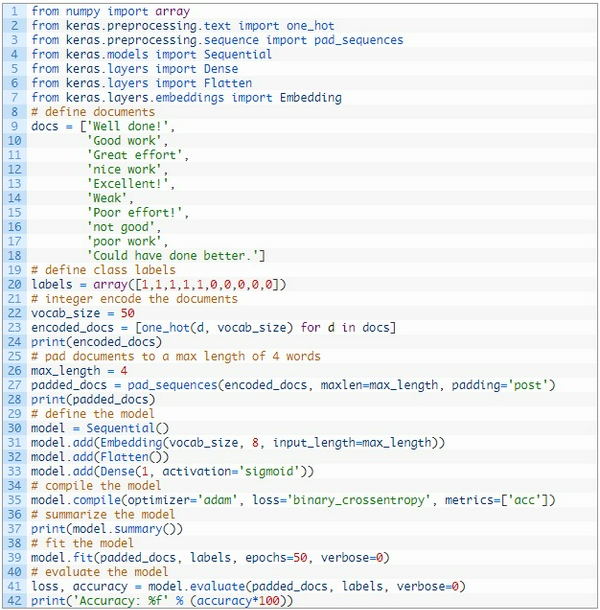
4. Ví dụ việc nhúng GloVe Embedding đã được train từ trước.
Dưới đây tôi sẽ sử dụng bộ từ điển đã được train từ trước và bộ dữ liệu tôi dùng là
Ví dụ mà tôi làm được lấy cảm hứng từ một dự án Keras:
Sau khi tải bộ dữ liệu trên, bạn sẽ nhận được một vài file, một trong số chúng là glove.6B.100d.txt chứa phiên bản 100 chiều.
Keras cung cấp một Tokenizer giúp việc sử dụng bộ dữ liệu đã train, có thể chuyển đổi từ văn bản thành chuỗi liên tục đó là text_to_sequences() và cung cấp truy cập từ điển ánh xạ từ tới số nguyên trong thuộc tính word_index.
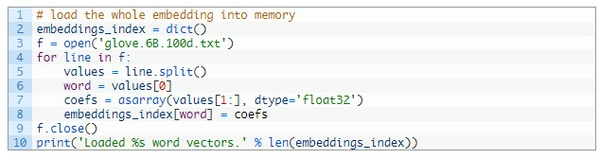
Tiếp theo ta cần load từ điển từ trong GloVe ra:
Tiếp theo ta cần tạo ra một ma trận cho mỗi từ được huấn luyện. Chúng ta có thể làm điều này bằng cách liệt kê tất cả các từ duy nhất trong Tokenizer.word_index và xác định weights từ việc lấy sẵn bộ từ điển GloVe đã tải.

Có thể coi là đã xong khâu chuẩn bị. Bây giờ ta có thể xác định mô hình để phù hợp và đánh giá nó như ở ví dụ trước.
Điểm khác biệt ở đây là lớp nhúng có thể được ghép với GloVe. Tôi đã chọn phiên bản 100 chiều, do đó output_dim của tôi sẽ phải đổi thành 100. Tôi không muốn cập nhật từ đã học nên tôi sẽ để thuộc tính trainable là False:

Dưới đây là đoạn code hoàn chỉnh của tôi:
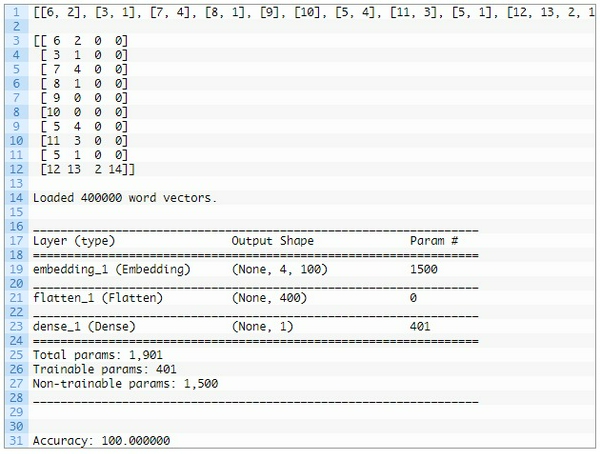
Dưới đây là kết quả run được:
Trên thực tế, thường tôi sẽ khuyến khích bạn dùng một word embedding bằng cách sử dụng từ đã được train trước đó hơn.
Trong ví dụ này bạn đã học được cách sử dụng word embedding vào việc phân loại văn bản. Mong rằng bài viết sẽ giúp ích được cho các bạn khi mới học về NLP (xử lý ngôn ngữ tự nhiên).
Tham khảo: How to Use Word Embedding Layers for Deep Learning with Keras