Kiến trúc cơ bản một hệ thống dữ liệu lớn
#BigDataArchitecture
#DataLake
Một hệ thống dữ liệu lớn (BigData) ở mỗi doanh nghiệp sẽ được triển khai khác nhau, tuỳ thuộc vào mô hình kinh doanh của doanh nghiệp, đặc điểm dữ liệu, và phụ thuộc vào đầu tư mà sẽ được thiết kế, xây dựng trên các bộ giải pháp công nghệ khác nhau. Tuy vậy, các bạn đều có thể tham khảo chung 1 kiến trúc chung, có tính tổng quát như sau:
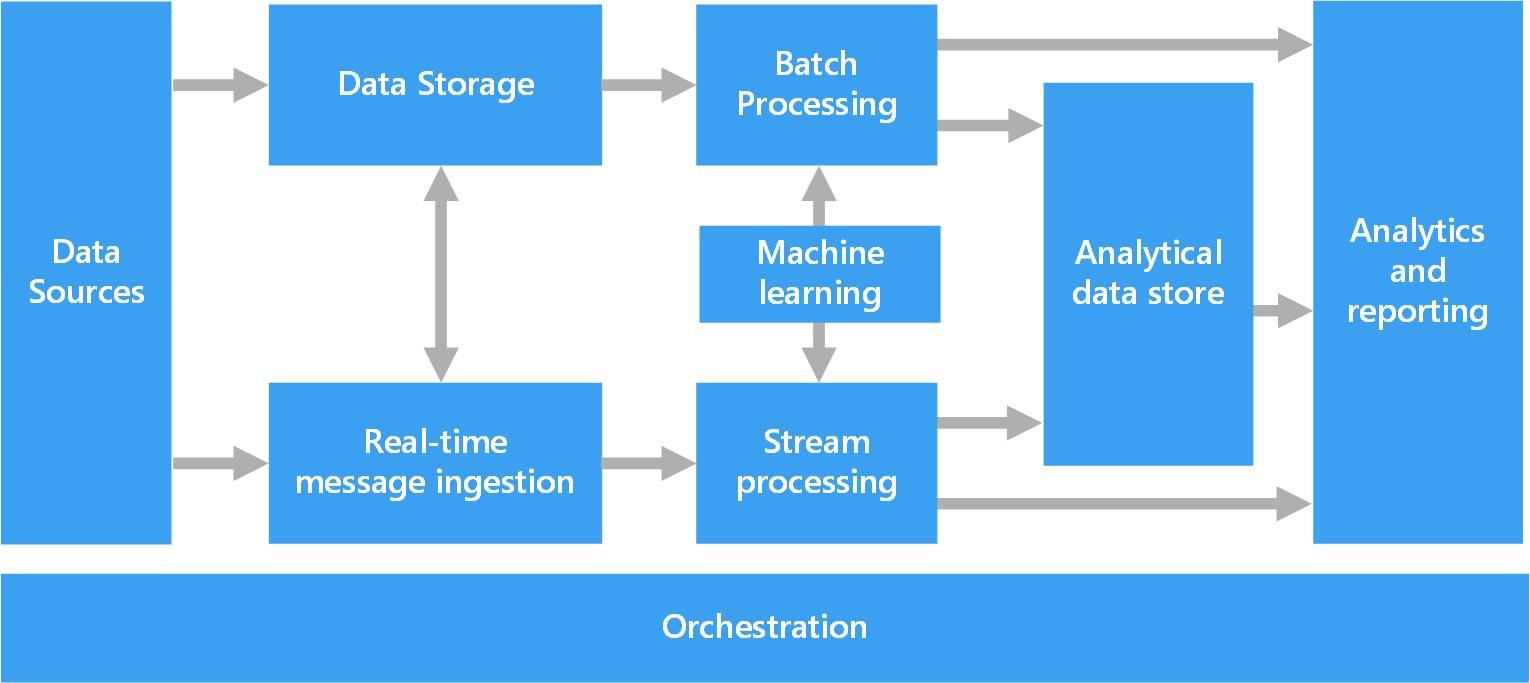
Nguồn ảnh Microsoft
Đây là một kiến trúc xử lý chung cho các hệ thống Big Data. Nó bao gồm các thành phần:
- Nguồn dữ liệu (Data Sources): nơi dữ liệu được sinh ra, bao gồm dữ liệu có cấu trúc (structure), dữ liệu phi cấu trúc (un-structure) cũng như dữ liệu bán cấu trúc (semi-structure). Dữ liệu có thể đến từ rất nhiều nguồn khác nhau như dữ liệu từ các ứng dụng, cơ sở dữ liệu quan hệ (giao dịch mua/ bán hàng từ một hệ thống bán lẻ, giao dịch gửi tiền vào ngân hàng, …), hoặc dữ liệu file được tạo ra bởi các log của ứng dụng (dữ liệu log ghi lại thời gian xử lý của hệ thống, …), hay dữ liệu thời gian thực từ các thiết bị IoT (hình ảnh theo dõi từ camera, cảm biến nhiệt độ, độ ẩm, ….)
- Lưu trữ dữ liệu (Data Storage): thành phần này được thiết kế để lưu trữ lại khối lượng rất lớn các loại dữ liệu với các định dạng khác nhau được sinh ra bởi nguồn dữ liệu (Data Source) trong mô hình xử lý dữ liệu theo lô (Batch Processing). Mô hình phổ biến cho thành phần này là các hệ thống lưu trữ file phân tán trên nhiều node khác nhau trong 1 cụm (cluster), đảm bảo cho khả năng xử lý lượng rất lớn các file dữ liệu cũng như tính an toàn của dữ liệu (replica). Apache Hadoop HDFS đang được sử dụng phổ biến để implement thành phần này trong các hệ thống Big Data.
- Xử lý dữ liệu theo lô (Batch Processing): thành phần này cho phép xử lý một lượng lớn dữ liệu thông qua việc đọc dữ liệu từ các file nguồn, lọc dữ liệu theo các điều kiện nhất định, tính toán trên dữ liệu, và ghi kết quả xuống 1 file đích. Trong thành phần này bạn có thể sử dụng Spark, Hive, MapReduce, … với nhiều ngôn ngữ lập trình khác nhau như Java, Scala hoặc Python.
- Thu thập dữ liệu thời gian thực (Real-time Message Ingestion): như đã nói ở trên, dữ liệu được sinh ra từ nguồn (Data Source) có thể bao gồm dữ liệu thời gian thực (ví dụ từ các thiết bị IoT) do đó thành phần này cho phép một hệ thống Big Data có thể thu thập và lưu trữ các loại dữ liệu trong thời gian thực phục vụ cho việc xử lý dữ liệu theo luồng (Streaming Processing). Công nghệ phổ biến nhất chắc các bạn hay nghe đến Kafka, ngoài ra còn có những cái tên khác như RabbitMQ, ActiveMQ, … và gần đây là Apache Pulsarvới so sánh nhanh hơn 2.5 lần và độ trễ thấp hơn 40% so với Kafka (bạn nào đã từng so sánh 2 chú này confirm lại nhận định trên cái 😊)
- Xử lý dữ liệu theo luồng (Stream Processing): tương tự như việc xử lý dữ liệu theo lô (Batch Processing), sau khi thu thập dữ liệu thời gian thực, dữ liệu cũng cần phải được lọc theo các điều kiện nhất định, tính toán trên dữ liệu, và ghi kết quả dữ liệu sau khi được xử lý. Chúng ta có thể nhắc đến Apache Storm, Spark Streaming, …
- Lưu trữ dữ liệu phân tích (Analytical Data Store): chịu trách nhiệm lưu trữ dữ liệu đã được xử lý theo định dạng có cấu trúc để phục vụ cho các công cụ phân tích dữ liệu (BI Tools). Dữ liệu có thể được lưu trữ dưới dạng OLAP trong thiết kế Kimball (cho bạn nào chưa biết thì Kimball là một trong 3 phương pháp luận khi thiết kế 1 data warehouse: Inmon, Kimball và Data Vault) hoặc dữ liệu có thể lưu trữ bằng các công nghệ NoQuery như HBase, Cassandra, …
- Lớp phân tích và báo cáo (Analysis and Reporting): thành phần này đáp ứng việc tự khai thác dữ liệu data self-service. Cho phép người dùng cuối trực quan hóa dữ liệu (data visualization), phân tích dữ liệu, cũng như kết xuất các báo cáo khác nhau. Công nghệ được sử dụng ở tầng này khá đa dạng, có thể là các open source tool như D3.JS, Dygaphs, … đến các công cụ commercial như Tableau, Power BI, …, hay bạn có thể tự code bằng các ngôn ngữ Python, R, …
- Điều phối (Orchestration): thành phần này có nhiệm vụ điều phối các công việc trong một hệ thống Big Data để đảm bảo luồng xử lý dữ liệu được thông suốt, từ việc thu thập dữ liệu, lưu trữ dữ liệu đến lọc, tính toán trên dữ liệu. Apache Oozie, Airflow, …đổi hay không.
datamining
,trí tuệ nhân tạo
Nội dung liên quan