Hiểu về nhận dạng khuôn mặt thông qua thuật toán OpenFace
Hệ thống nhận diện khuôn mặt đã trở thành một công nghệ ngày càng phổ biến.
Ngày nay, điện thoại thông minh sử dụng nhận dạng khuôn mặt để kiểm soát truy cập và phim hoạt hình sử dụng phần mềm nhận dạng khuôn mặt để mang lại sự chuyển động và biểu cảm chân thực của con người, camera giám sát của cảnh sát sử dụng nó để xác định những người đã ra lệnh bắt giữ họ và nó cũng đang được sử dụng trong các cửa hàng bán lẻ cho các chiến dịch tiếp thị tầm nhìn, cũng có thể là các hệ thống điểm danh nhân viên công ty. Và tất nhiên, ứng dụng gắn thẻ tự động của Facebook cũng sử dụng nhận dạng khuôn mặt để gắn thẻ khuôn mặt.
Không phải tất cả các thư viện nhận dạng khuôn mặt đều có độ chính xác và hiệu suất như nhau, và hầu hết các hệ thống hiện đại đều là “proprietary black box” hộp đen kín (tức không công khai cho công đồng mã nguồn sử dụng).
OpenFace là một thư viện mã nguồn mở với hiệu suất và độ chính xác của các mô hình “proprietary black box”.
Tổng quan kiến trúc cấp cao
OpenFace là một mô hình nhận dạng khuôn mặt học sâu được phát triển bởi Brandon Amos, Bartosz Ludwiczuk và Mahadev Satyanarayanan. Nó dựa trên bài báo:
Mặc dù OpenFace chỉ mới công khai được vài năm, nhưng nó đã được áp dụng rộng rãi bởi vì nó cung cấp các mức độ chính xác tương tự như các mô hình nhận dạng khuôn mặt các hệ thống hiện đại như FaceNet của Google hay DeepFace của Facebook.
Điều đặc biệt tốt về OpenFace, ngoài việc là nguồn mở, là sự phát triển của mô hình tập trung vào nhận dạng khuôn mặt thời gian thực (real-time) trên thiết bị di động, vì vậy bạn có thể huấn luyện một mô hình với độ chính xác cao với rất ít dữ liệu.
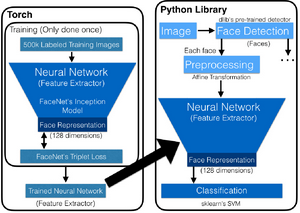
OpenFace sử dụng Torch, một framework để huấn luyện ngoại tuyến, nghĩa là nó chỉ được thực hiện một lần bởi OpenFace và người dùng không phải tự mình huấn luyện hàng trăm ngàn hình ảnh. Những hình ảnh đó sau đó được ném vào mạng neuron để trích xuất đặc trưng bằng mô hình Inception của FaceNet. FaceNet dựa vào hàm triplet loss để tính toán độ chính xác của mạng neuron phân loại một khuôn mặt và có thể phân cụm các khuôn mặt.
Mạng neuron được huấn luyện này sau đó được sử dụng sau khi các hình ảnh mới được chạy qua mô hình nhận diện khuôn mặt của dlib. Các khuôn mặt được chuẩn hóa bằng phép biến đổi affine của OpenCV, nên tất cả các khuôn mặt được định hướng theo cùng một hướng, chúng được gửi qua mạng neuron được huấn luyện trong một lần chuyển tiếp. Điều này dẫn đến đầu ra là 128 embeddings là mặt được sử dụng để phân loại cho việc so khớp hoặc thậm chí có thể được sử dụng trong thuật toán phân cụm để phát hiện sự tương tự (similarity detection).
Huấn luyện
Trong phần huấn luyện của OpenFace, 500.000 hình ảnh được truyền qua mạng neuron. Những hình ảnh này được lấy từ hai bộ dữ liệu công khai: CASIA-WebFace, bao gồm 10.575 cá nhân với tổng số 494.414 hình ảnh và FaceScrub, được tạo thành từ 530 cá nhân với tổng số 106.863 hình ảnh.
Quan điểm của việc huấn luyện theo đường ống mạng neuron trên tất cả các hình ảnh này là nó có thể thực hiện trên điện thoại di động hoặc bất kỳ kịch bản thời gian thực nào khác để huấn luyện 500.000 hình ảnh để lấy ra các facial embeddings cần thiết. Bây giờ hãy nhớ rằng, phần này của đường ống chỉ được thực hiện một lần vì OpenFace huấn luyện những hình ảnh này để tạo ra 128 facial embeddings đại diện cho một khuôn mặt chung sẽ được sử dụng sau này trong phần huấn luyện. Sau đó, thay vì so khớp một hình ảnh trong không gian đa chiều, bạn chỉ sử dụng dữ liệu chiều thấp, giúp mô hình này nhanh.
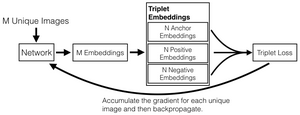
Như đã đề cập trước đó, OpenFace sử dụng kiến trúc Google FaceNet để trích xuất đặc trưng và sử dụng hàm triplet loss để kiểm tra mức độ chính xác của mạng phân loại một khuôn mặt. Nó thực hiện điều này bằng cách huấn luyện trên ba hình ảnh khác nhau trong đó một hình ảnh khuôn mặt được gọi là anchor (đầu vào), sau đó một hình ảnh khác của cùng một người positive, trong khi hình ảnh thứ 3 là hình ảnh của một người khác (negative).
Điều tuyệt vời khi sử dụng triple embedding là các lần embedding được đo trên một siêu phẳng đơn vị nơi khoảng cách Euclide được sử dụng để xác định hình ảnh nào gần nhau hơn và cách xa nhau hơn. Điều này rất quan trọng vì nó cho phép các thuật toán phân cụm được sử dụng để phát hiện sự tương tự. Bạn có thể muốn sử dụng thuật toán phân cụm nếu bạn muốn phát hiện các thành viên gia đình trên một trang phả hệ, hoặc trên phương tiện truyền thông xã hội cho các chiến dịch tiếp thị.
Cô lập khuôn mặt từ phông nền ảnh

Bây giờ chúng tôi đã giới thiệu cách OpenFace sử dụng Torch để huấn luyện hàng trăm ngàn hình ảnh từ các bộ dữ liệu cộng đồng để có được các facial embedding, chúng tôi có thể kiểm tra việc sử dụng thư viện nhận diện khuôn mặt phổ biến của họ như dlib và xem tại sao bạn muốn sử dụng nó thay vì thư viện nhận diện khuôn mặt của OpenCV.
Một trong những bước đầu tiên trong phần mềm nhận diện khuôn mặt là cách ly khuôn mặt thực tế khỏi nền của hình ảnh cùng với cách ly từng khuôn mặt với những người khác được tìm thấy trong hình ảnh. Các thuật toán phát hiện khuôn mặt cũng phải có khả năng xử lý ảnh không tốt và không nhất quán và các vị trí khuôn mặt khác nhau như mặt nghiêng,.... May mắn, dlib cùng với OpenCV xử lý tất cả các vấn đề này. Dlib đảm nhiệm việc tìm kiếm các điểm fiducial (các điểm landmark chính trên khuôn mặt) trên khuôn mặt trong khi OpenCV xử lý việc bình thường hóa vị trí khuôn mặt.
Điều quan trọng cần lưu ý là khi sử dụng OpenFace, bạn có thể triển khai dlib để phát hiện khuôn mặt, sử dụng kết hợp HOG, SVM hoặc Haar cascade của OpenCV. Cả hai đều được huấn luyện về ảnh positive và negative (có nghĩa là có những hình ảnh có khuôn mặt và hình ảnh không phù hợp), nhưng chúng rất khác nhau về cách thực hiện, tốc độ và độ chính xác.
Có một số lợi ích khi sử dụng trình phân loại HOG. Đầu tiên, việc huấn luyện được thực hiện bằng cách sử dụng cửa sổ trượt trên hình ảnh để không cần thao tác lấy mẫu con và tham số giống như trong phân loại Haar. Điều này làm cho đặc trưng nhận diện khuôn mặt của dlib như HOG và SVM dễ sử dụng hơn và nhanh hơn để huấn luyện. Nó cũng có nghĩa là ít dữ liệu được yêu cầu. Lưu ý rằng HOG có độ chính xác cao hơn để phát hiện khuôn mặt so với Haar cascade.
Tiền sử lý ảnh
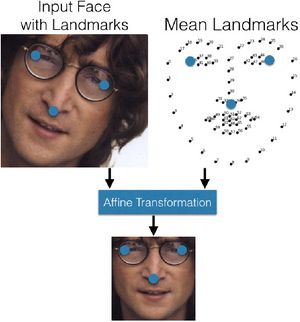
Cùng với việc tìm kiếm từng khuôn mặt trong một hình ảnh, một phần của quá trình nhận dạng khuôn mặt là xử lý trước các hình ảnh để xử lý các vấn đề như ánh sáng không nhất quán và xấu, chuyển đổi hình ảnh sang thang độ xám (grayscale) để huấn luyện nhanh hơn và bình thường hóa vị trí khuôn mặt.
Mặc dù một số mô hình nhận dạng khuôn mặt có thể xử lý các vấn đề này bằng cách huấn luyện trên các bộ dữ liệu lớn, dlib sử dụng phép biến đổi 2D Affine, giúp xoay khuôn mặt và làm cho vị trí của mắt, mũi và miệng phù hợp với từng khuôn mặt. Có 68 mốc mặt được sử dụng trong chuyển đổi affine để phát hiện đặc điểm và khoảng cách giữa các điểm đó được đo và so sánh với các điểm được tìm thấy trong hình ảnh khuôn mặt trung bình. Sau đó, ảnh được xoay và biến đổi dựa trên những điểm đó để chuẩn hóa khuôn mặt để so sánh và được cắt thành 96 × 96 pixel để đưa vào mạng neuron được huấn luyện.
Phân loại
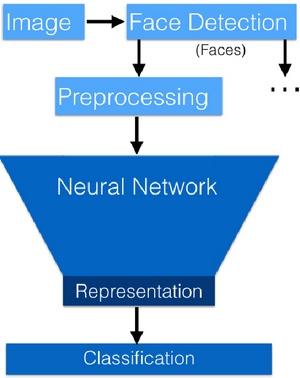
Vì vậy, sau khi tách ảnh khỏi nền và tiền xử lý bằng cách sử dụng dlib và OpenCV, chúng ta có thể chuyển hình ảnh vào mạng được huấn luyện được tạo ra trong phần Torch của đường ống. Trong bước này, có một chuyển tiếp duy nhất trên mạng thần kinh để có được 128 embedding (đặc điểm khuôn mặt) được sử dụng trong dự đoán. Những facial embedding này sau đó được sử dụng trong các thuật toán phân loại hoặc phân cụm. Đối với các thử nghiệm phân loại, OpenFace sử dụng máy SVM tuyến tính thường được sử dụng để so khớp với các đặc trưng của ảnh. Một điều ấn tượng về OpenFace là tại thời điểm này, chỉ mất vài mili giây để phân loại hình ảnh.
Nguồn:
