Giới thiệu về thuật toán K-means Clustering trong Machine Learning
Trong ngành khoa học dữ liệu, ta thường nghĩ đến việc sử dụng dữ liệu để huấn luyện mô hình và tạo các dự đoán đối với dữ liệu mới. Đó gọi là học có giám sát (supervised learning). Tuy nhiên, nhiều lúc chúng ta không muốn tạo các dự đoán mà muốn tìm điểm các tương đồng trong dữ liệu và phân dữ liệu vào các nhóm khác nhau. Đó gọi là học không giám sát (unsupervised learning). Chi tiết hơn về sự khác biệt giữa học có giám sát và học không giám sát mời các bạn đọc tại: https://noron.vn/post/su-khac-biet-giua-phuong-phap-hoc-co-giam-sat-va-hoc-khong-giam-sat-trong-machine-learning-529827389610418749?ref=97249675912513823.
Phân cụm là một trong những dạng học không giám sát được ứng dụng nhiều nhất. Trong bài viết này, chúng ta sẽ tìm hiểu về K-means Clustering, một thuật toán được sử dụng phổ biến vì sự đơn giản trong tính toán và tốc độ xử lý nhanh.
Thuật toán phân cụm K-means
Để có một cái nhìn tốt hơn, chúng ta sẽ mô phỏng lại cách hoạt động của thuật toán thông qua biểu đồ. Việc đầu tiên là khởi tạo dữ liệu. Ta sẽ tạo dữ liệu gồm 4 cụm với mỗi cụm có 200 điểm dữ liệu, mỗi điểm dữ liệu là một tọa độ (x, y) trong hệ trục 0xy. Công việc của chúng ta là phân các điểm dữ liệu này về các cụm. Để khởi tạo dữ liệu ta sử dụng hàm make_blobs trong thư viện sklearn:
Dưới đây là hình ảnh các điểm dữ liệu:
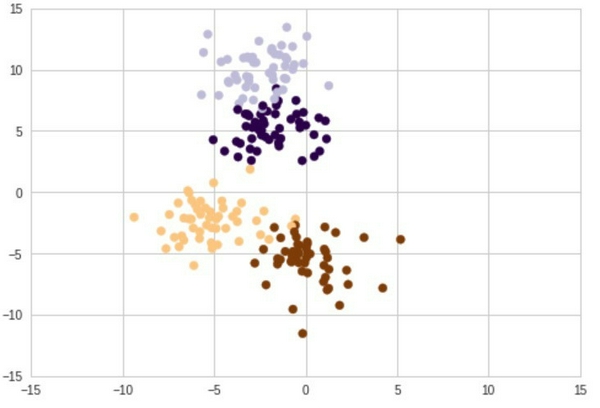
Ta có 4 cụm với màu sắc khác nhau, tuy nhiên giữa các cụm có sự chồng chéo về các điểm dữ liệu. Bây giờ ta giả sử rằng cũng với các điểm dữ liệu như trên nhưng giờ ta không biết chúng thuộc cụm nào và bài toán đặt ra là phải phân được các điểm dữ liệu về các cụm với số lượng cụm cho trước. Thuật toán K-means sẽ giải quyết bài toán này.
Bước đầu tiên trong thuật toán K-means là chọn các điểm trung tâm (centroid) cho mỗi cụm. Chúng ta giả sử rằng tồn tại 4 cụm với các điểm dữ liệu trên nên sẽ cần 4 điểm trung tâm, mỗi điểm trung tâm đại diện cho 1 cụm. Các điểm này được khởi tạo ngẫu nhiên và sẽ được cập nhật qua các vòng lặp của thuật toán. Bước tiếp theo, với mỗi điểm dữ liệu ta tìm cụm có điểm trung tâm gần điểm dữ liệu đó nhất. Để tính khoảng cách giữa các điểm, tôi sử dụng khoảng cách
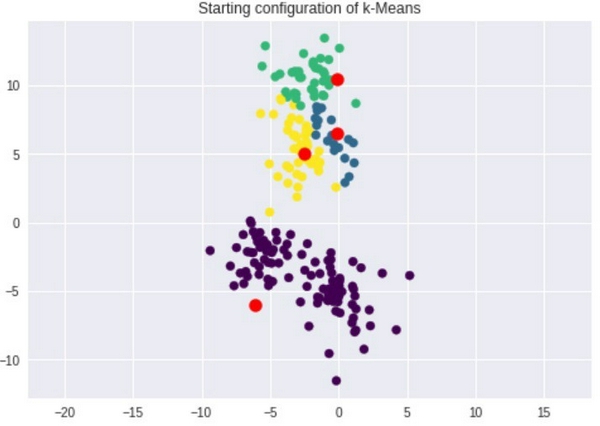
Giờ ta đã có 4 cụm, tuy nhiên vẫn chưa hợp lý vì 3 cụm phía trên ở quá gần nhau. Ta tiến hành cập nhật tọa độ các điểm trung tâm (x, y)c của các cụm bằng cách lấy giá trị trung bình của tất cả các điểm dữ liệu thuộc cụm đó:
(x, y)c = 1 / N * sum (x, y)i , i = [1, N]
với N là số lượng các điểm dữ liệu thuộc cụm đó. Sau khi cập nhật tọa độ các điểm trung tâm, ta lại xét từng điểm dữ liệu và gán nhãn cho các điểm dữ liệu đó theo cụm của điểm trung tâm gần nó nhất. Quá trình cập nhật các điểm trung tâm và gán nhãn cho các điểm dữ liệu sẽ được lặp đi lặp lai cho đến khi vị trí của các điểm trung tâm không đổi so với lần cập nhật gần nhất.
Dưới đây là kết quả cuối cùng của thuật toán:
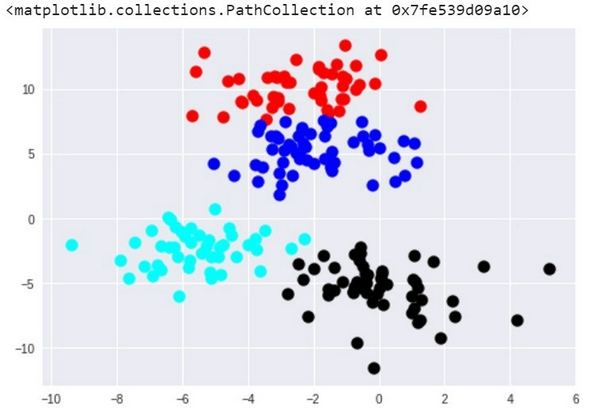
Cài đặt thuật toán K-means Clustering trên Python
Ta sử dụng thư viện

Sử dụng đoạn code phía trên để sinh các điểm dữ liệu và lưu vào mảng points, ta đưa các điểm dữ liệu vào thuật toán như sau:

Để biểu diễn kết quả, ta chạy đoạn code sau:

Có thể thấy được kết quả phân cụm rất giống với các cụm chúng ta đã khởi tạo từ trước. Như vậy thuật toán K-means đã hoàn thành rất tốt việc phân cụm cho các điểm dữ liệu.
Cảm ơn các bạn đã đọc bài viết :D