DNA Computings

Cuộc hành trình đến với máy tính phân tử
Máy tính DNA thực hiện các tính toán, xử lý dữ liệu, lưu trữ,... bằng cách sử dụng các phân tử sinh học thay vì sử dụng các loại chip sillicon thông thường ( như chúng ta đã biết loại chip đã đạt đến giới hạn nhỏ nhất)
Ý tưởng đầu tiên
Vào năm 1959, khi nhà Vật lý người Mỹ Richard Feynman trình bày ý tưởng của ông về công nghệ nano. Tuy nhiên điện toán DNA không được xem xét cho tới tận năm 1994, khi mà nhà khoa học máy tính người Mỹ Leonard Adleman chỉ ra các phân tử có thể được sử dụng để giải quyết các vấn đề tính toán.
Giải quyết các vấn đề với các phân tử DNA
Một tính toán có thể được coi là sự thực thi của một thuật toán , bản thân nó có thể được định nghĩa là một danh sách từng bước của các hướng dẫn được xác định rõ có một số đầu vào, xử lý nó và tạo ra kết quả. TrongĐiện toán DNA, thông tin được biểu diễn bằng bảng chữ cái di truyền gồm bốn ký tự (A [ adenine ], G [ guanine ], C [ cytosine ] và T [ thymine ]), thay vì bảng chữ cái nhị phân (1 và 0) được sử dụng bởi các máy tính truyền thống . Điều này có thể đạt được vì các phân tử DNA ngắncủa bất kỳ chuỗi tùy ý có thể được tổng hợp để đặt hàng. Do đó, đầu vào của thuật toán được đại diện (trong trường hợp đơn giản nhất) bằng các phân tử DNA với các trình tự cụ thể, các hướng dẫn được thực hiện bằng các thao tác trong phòng thí nghiệm trên các phân tử (chẳng hạn như sắp xếp chúng theo chiều dài hoặc cắt các chuỗi có chứa một chuỗi nhất định) và kết quả được định nghĩa là một số tính chất của tập hợp các phân tử cuối cùng (chẳng hạn như sự hiện diện hay vắng mặt của một chuỗi cụ thể).
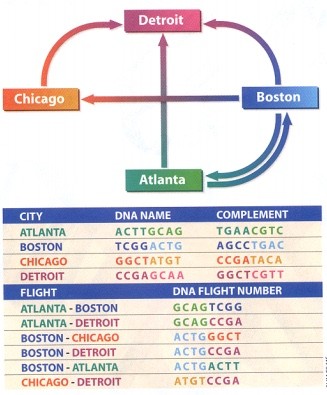
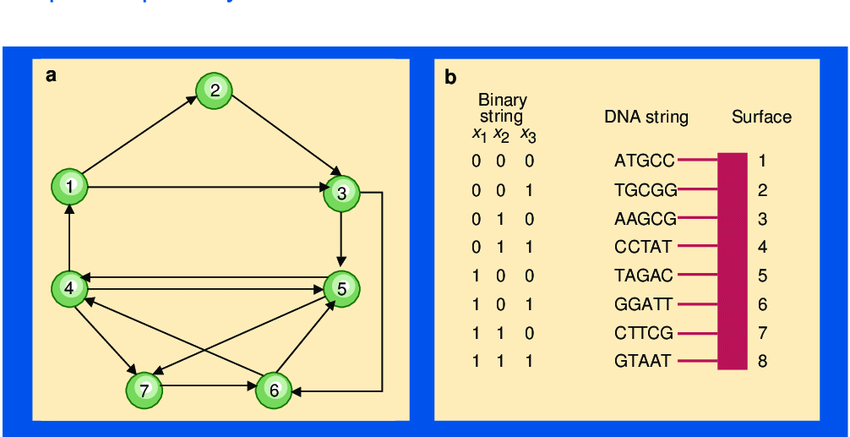
Thử nghiệm của Adman liên quan đến việc tìm tuyến đường qua mạng lưới thị trấn của thành phố (được gắn nhãn là 1 1 đến đường 7 7) được kết nối bởi các đường một chiều. Một vấn đề chỉ ra rằng tuyến đường phải bắt đầu và kết thúc tại các thị trấn cụ thể và ghé thăm từng thị trấn cụ thể thị trấn chỉ một lần. (Điều này được các nhà toán học gọi là vấn đề con đường Hamilton, một người anh em họ của vấn đề nhân viên bán hàng du lịch nổi tiếng hơn .) Adman đã tận dụng lợi thế của Watson - Crick thuộc tính bổ sung của DNA DNA A và T kết hợp với nhau theo kiểu cặp đôi, cũng như G và C (vì vậy trình tự AGCT sẽ bám hoàn hảo vào TCGA). Ông đã thiết kế các chuỗi DNA ngắn để đại diện cho các thị trấn và các con đường sao cho các chuỗi đường này kết nối các chuỗi thị trấn lại với nhau, tạo thành chuỗi các thị trấn đại diện cho các tuyến đường (như giải pháp thực tế, tình cờ có tên là 123 1236767). Hầu hết các trình tự như vậy đại diện cho câu trả lời không chính xác cho vấn đề này nồi sợi. Vấn đề là sau đó giải nén giải pháp độc đáo này. Ông đã đạt được điều này bằng cách khuếch đại đầu tiên (sử dụng một phương pháp được gọi là phản ứng chuỗi polymerase[PCR]) chỉ những chuỗi bắt đầu và kết thúc ở đúng thị trấn. Sau đó, anh ta sắp xếp các chuỗi theo chiều dài (sử dụng một kỹ thuật gọi là điện di gel) để đảm bảo rằng anh ta chỉ giữ lại các chuỗi có độ dài chính xác. Cuối cùng, anh ta liên tục sử dụng một cần câu phân tử c (thanh lọc ái lực) để đảm bảo rằng mỗi thị trấn lần lượt được thể hiện trong các chuỗi ứng cử viên. Các sợi Adman bị bỏ lại sau đó được giải trình tự để tiết lộ giải pháp cho vấn đề.
Mặc dù Adman chỉ tìm cách thiết lập tính khả thi của điện toán với các phân tử, ngay sau khi công bố, thí nghiệm của ông được một số người trình bày là sự khởi đầu của một cuộc cạnh tranh giữa các máy tính dựa trên DNA và các đối tác silicon của họ. Một số người tin rằng một ngày nào đó máy tính phân tử có thể giải quyết các vấn đề khiến máy móc hiện tại phải vật lộn, do sự song song lớn vốn có của sinh học . Bởi vì một giọt nước nhỏ có thể chứa hàng nghìn tỷ chuỗi DNA và do các hoạt động sinh học tác động lên tất cả chúng, song song với nhau một cách hiệu quả (trái ngược với từng lúc), người ta cho rằng một ngày nào đó máy tính DNA có thể đại diện (và giải quyết) những vấn đề khó khăn vượt ra ngoài phạm vi của các máy tính bình thường.
Tuy nhiên, trong hầu hết các vấn đề khó khăn, số lượng giải pháp có thể tăng theo cấp số nhân với quy mô của vấn đề (ví dụ: số lượng giải pháp có thể tăng gấp đôi cho mỗi thị trấn được thêm vào). Điều này có nghĩa là các vấn đề tương đối nhỏ sẽ đòi hỏi khối lượng DNA không thể quản lý (theo thứ tự các bồn tắm lớn) để thể hiện tất cả các câu trả lời có thể. Thí nghiệm của Adman rất có ý nghĩa vì nó đã thực hiện các tính toán quy mô nhỏ với các phân tử sinh học. Quan trọng hơn, tuy nhiên, nó đã mở ra khả năng của các phản ứng sinh hóa được lập trình trực tiếp.
Công Nghệ Thông Tin Dựa Trên Hóa Sinh
Lập trình hóa học thông tin sẽ cho phép xây dựng các loại mới hệ thống sinh hóa có thể cảm nhận môi trường xung quanh của chính họ, hành động theo quyết định và thậm chí có thể giao tiếp với các hình thức tương tự khác. Mặc dù các phản ứng hóa học xảy ra ở cấp độ nano, cái gọi là công nghệ thông tin dựa trên hóa sinh (bio / chem IT) khác vớicông nghệ nano , do sự phụ thuộc của trước đây vào các hệ thống phân tử quy mô tương đối lớn.
Mặc dù CNTT sinh học / hóa học hiện đại sử dụng nhiều loại hệ thống hóa học (sinh học) khác nhau, công việc ban đầu trên các hệ thống phân tử lập trình chủ yếu dựa trên DNA . Nhà hóa sinh người MỹNadrian Seeman là người tiên phong đầu tiên của công nghệ nano dựa trên DNA, ban đầu sử dụng phân tử đặc biệt này hoàn toàn như là một giàn giáo có kích thước nano để điều khiển và kiểm soát các phân tử khác. Nhà khoa học máy tính người MỹErik Winfree đã làm việc với Seeman để chỉ ra cách thức các tấm lát hai chiều, các loại gạch lát nền dựa trên DNA, (các hình chữ nhật được tạo thành từ các chuỗi DNA đan xen) có thể tự lắp ráp thành các cấu trúc lớn hơn. Vô dụng, cùng với học sinh của mìnhPaul Rothemun d, sau đó đã chỉ ra làm thế nào những viên gạch này có thể được thiết kế sao cho quá trình tự lắp ráp có thể thực hiện một tính toán cụ thể. Sau đó, Rothemund đã mở rộng công việc này với nghiên cứu về Origami DNA origami, trong đó một chuỗi DNA được gấp lại nhiều lần thành hình dạng hai chiều, được hỗ trợ bởi các chuỗi ngắn hoạt động như các mặt hàng chủ lực.
Các thí nghiệm khác đã chỉ ra rằng các tính toán cơ bản có thể được thực hiện bằng cách sử dụng một số khối xây dựng khác nhau (ví dụ, các máy phân tử đơn giản, có thể sử dụng kết hợp DNA và enzyme dựa trên protein). Bằng cách khai thác sức mạnh của các phân tử, các hình thức công nghệ xử lý thông tin mới có thể phát triển, tự sao chép, tự sửa chữa và đáp ứng. Các ứng dụng khả thi của công nghệ mới nổi này sẽ có tác động đến nhiều lĩnh vực, bao gồm chẩn đoán y tế thông minh và phân phối thuốc, kỹ thuật mô , năng lượng và môi trường .