Deep Learning: Giới thiệu về mạng Neurons và các hàm Activation
Bài viết này sẽ giới thiệu tổng quát về các khái niệm và thuật ngữ được sử dụng trong Deep Learning.
Artificial Neural Network - Mạng neural
Mạng neural là một mô hình có khả năng học được các khuôn mẫu phức tạp của dữ liệu qua các lớp (layer) neurons có nhiệm vụ biến đổi dữ liệu theo các công thức toán học. Các lớp neurons nằm giữa đầu vào (input layer) và đầu ra (output layer) được gọi là hidden layers. Một mạng neural có thể khám phá và học các mối quan hệ giữa các thuộc tính của dữ liệu và sử dụng các quan hệ này để đưa ra dự đoán. Dưới đây là ví dụ về 1 mạng neural:
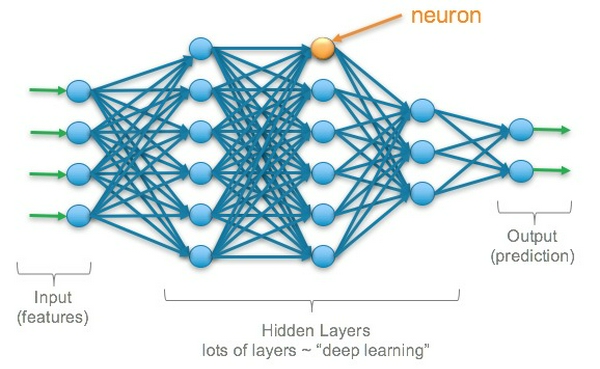
Mạng neural phía trên được gọi là Multilayer Perceptron (MLP). Một mạng MLP phải có ít nhất 3 layers: input, hidden và output. Các layer này được kết nối hoàn toàn với nhau: Mỗi nút ở từng layer đều kết nối với tất cả các nút của layer kế tiếp. Thuật ngữ "deep learning" được sử dụng để ám chỉ mô hình Machine Learning được xây dựng với rất nhiều hidden layers và còn được gọi là Deep Neural Network.
Neuron
Một neuron nhân tạo (còn được gọi là percepton) là một hàm biến đổi toán học nhận một hoặc nhiều đầu vào đã được nhân với các giá trị gọi là "weights", cộng các giá trị đó lại với nhau thành một giá trị duy nhất. Sau đó giá trị này được đưa vào một hàm phi tuyến (được gọi là activation function) và kết quả của hàm này chính là đầu ra của neuron.
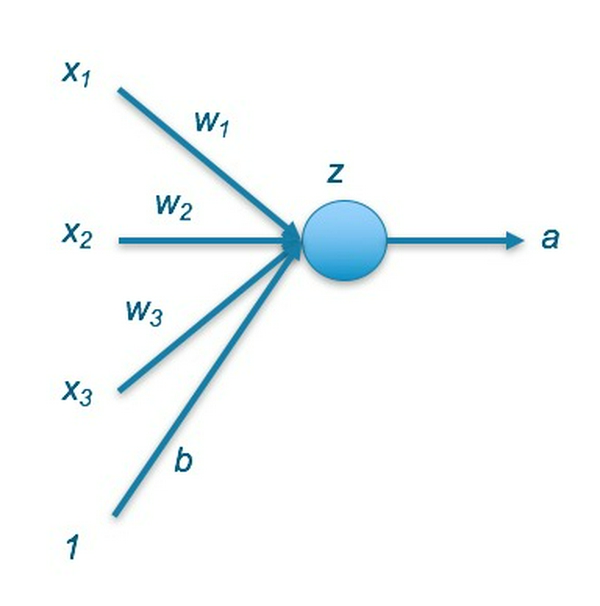
Ta có:
- x biểu diễn các giá trị đầu vào của neuron hiện tại
- w là các giá trị weights có tác dụng biến đổi các giá trị đầu vào thành một định dạng có cấu trúc mà máy có thể hiểu được
- b là giá trị bias có tác dụng tăng sự linh hoạt trong việc học dữ liệu
- z là giá trị trước khi đi vào hàm phi tuyến, được tính theo công thức:
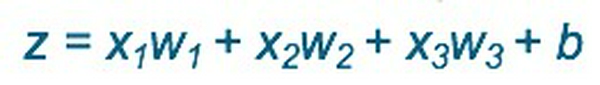
- a là giá trị cuối cùng và là đầu ra của neuron hiện tại, sẽ được truyền đến tất cả neuron được nối với neuron hiện tại của hidden layer kế tiếp hoặc được xử lý như là kết quả cuối cùng của mô hình.
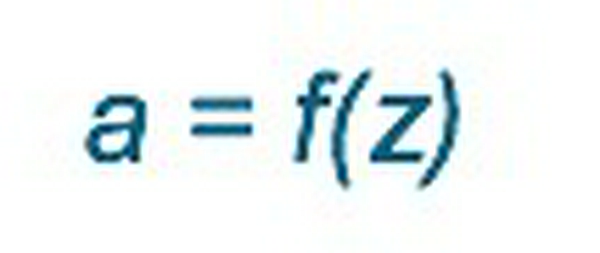
Activation Function
Là một hàm phi tuyến được áp dụng cho các neuron để đưa tính chất phi tuyến vào trong mô hình. Dưới đây là các hàm activation phổ biến:
1. Linear Activation Function:
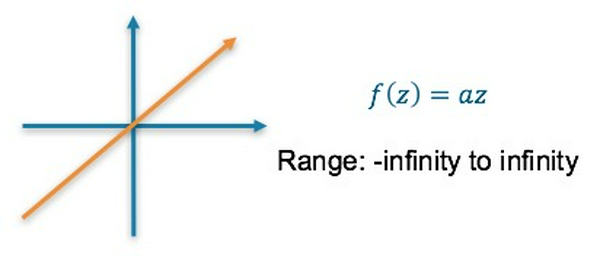
- Là hàm tuyến tính, trong đó a là một hằng số
- Kết quả cuối cùng có thể rất lớn
- Không nắm bắt được những cấu trúc phức tạp của dữ liệu
2. Sigmoid Activation Function
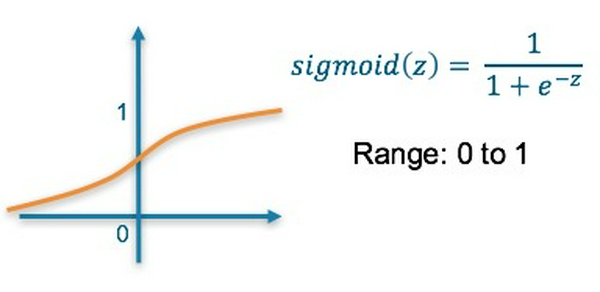
- Là hàm phi tuyến nên có tính linh hoạt hơn
- Kết quả cuối cùng được biến đổi về khoảng giá trị [0, 1]
- Có thể gặp trường hợp "vanishing gradient" khi huấn luyện mạng
3. Hyperbolic Tangent Activation Function
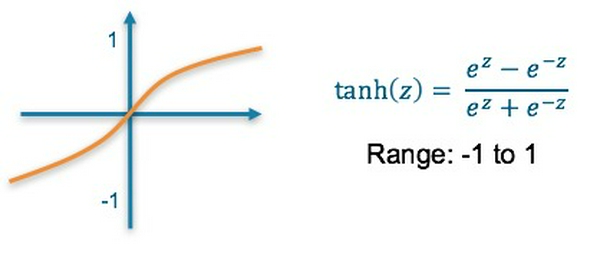
- Là hàm phi tuyến
- Kết quả cuối cùng được biến đổi về khoảng giá trị [0, 1]
- Có thể gặp trường hợp "vanishing gradient" khi huấn luyện mạng
4. Rectified Linear Unit (ReLU) Activation Function
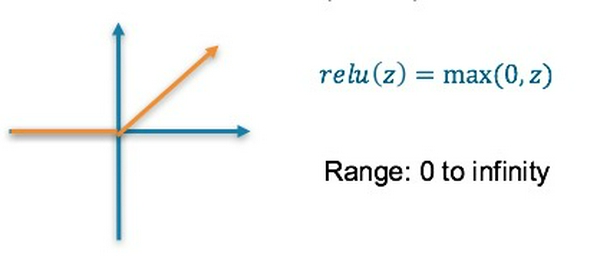
- Là hàm phi tuyến
- Kết quả cuối cùng có thể rất lớn
- Vì nó lọc những gía trị âm nên có thể sẽ bỏ qua những thông tin quan trọng
- Gradient có thể tiến về 0 nên các giá trị weights không được cập nhập ("dying ReLU")
5. Leaky ReLU Activation Function
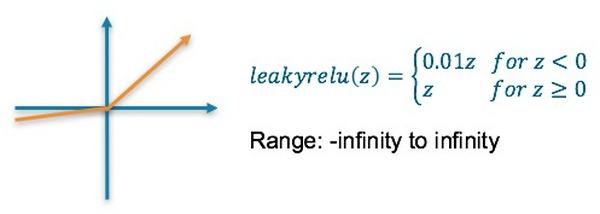
- Là hàm phi tuyến
- Được sinh ra để khắc phục vấn đề "dying ReLu"
- Kết quả cuối cùng có thể rất lớn
- Giá trj 0.01 có thể được thay bằng một tham số a được huấn luyện song song với các weights. Hàm này được gọi là Parametric ReLU (PReLU):
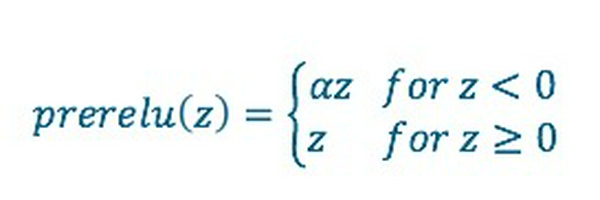
6. Softmax Activation Function

- Mỗi giá trị này trong khoảng [0, 1] và tổng tất cả giá trị bằng 1 nên được sử dụng để mô hình các phân phối xác suất.
- Chỉ được sử dụng tại output layer.
Kết luận
Bài viết này đã giới thiệu về các khái niệm cơ bản của mạng neural và các activation function. Cảm ơn các bạn đã đọc bài viết :D
Nguồn: Medium Deep Learning: Overview of Neurons and Activation Functions