Báo cáo phân loại văn bản sử dụng CNN, RNN & HAN (Phần 1: CNN)
Bài viết dưới đây được viết bởi tác giả Akshat Maheshwari chia sẻ về kinh nghiệm của mình trong bài toán phân loại văn bản. Dưới đây tôi sẽ dùng giọng văn của tác giả để các bạn dễ theo dõi nhé.
Giới thiệu:
Xin chào các bạn! gần đây tôi đã tham gia
Trong bài viết này, tôi sẽ chia sẻ kinh nghiệm và các bài học của tôi trong khi thử nghiệm với các kiến trúc mạng nơ-ron khác nhau.
Tôi sẽ cover 3 thuật toán chính dưới đây:
- Convolution Neural Network (CNN)
- Recurrent Neural Network (RNN)
- Hierarchical Attention Network (HAN)
Phân loại văn bản đã được tôi thực hiện trên các ngôn ngwxL Đan Mạch, Ý, Đức, Anh và Thổ Nhĩ Kỳ.
Nào, hãy bắt đầu thôi!
Natural Language Processing (NLP) - Xử lý ngôn ngữ tự nhiên
Một trong những vấn đề sử dụng NLP và học có giám sát (ML) là "Phân loại văn bản", đây là một ví dụ của học có giám sát từ nhãn và dữ liệu chứa trong một văn bản và những nhãn đó dùng để đào tạo một trình phân loại.
Mục tiêu của phân loại văn bản là tự động hóa phân loại văn bản vào một hoặc nhiều danh mục (chuyên mục) đã được xác định trước đó.
Một vài ví dụ của phân loại văn bản là:
- Phân loại cảm xúc của người viết bài (vui, buồn, tức giận...) từ mạng xã hội.
- Phát hiện thư rác
- Tự động gán nhãn các truy vấn của khách hàng.
- Phân loại các bài báo thành các chủ đề đã được xác định trước,
Phân loại văn bản là một lĩnh vực nghiên cứu rất tích cực cả trong học tập và trong các ngành công nghiệp. Trong bài viết này, tôi sẽ cố gắng trình bày một vài phương pháp tiếp cận khác nhau và so sánh hiệu quả của chúng, tôi triển khau dựa trên
Tất cả source code và kết quả thực nghiệm các bạn có thể tìm thấy ở
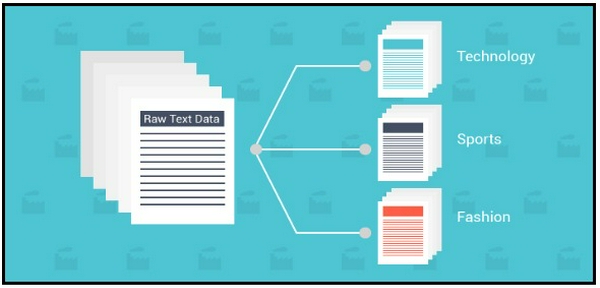
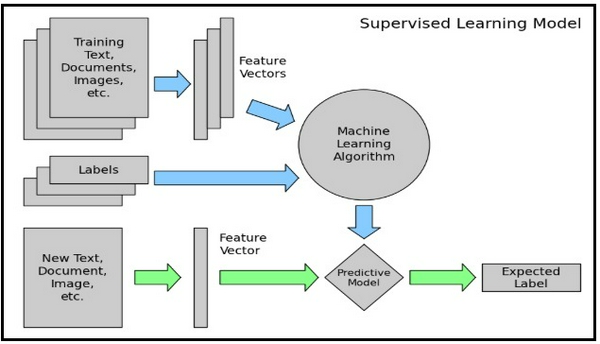
Một kiến trúc end-to-end phân loại văn bản bao gồm các thành phần sau:
- Văn bản cần training: Dữ liệu đầu vào mà mô hình học có giám sát của chúng ta có thể hiểu và dự đoán được các lớp cần thiết.
- Feature Vector: Một feature vector là một vector bao gồm thông tin chi tiết các đặc tính của dữ liệu đầu vào.
- Labels: Categories/ classes mà mô hình của chúng ta cần dự đoán.
- Thuật toán ML: Đây là thuật toán mà model của tôi có thể xử lý để phân loại văn bản (trong trường hợp này, tôi sử dụng: CNN, RNN, HAN)
- Dự đoán mô hình: Một mô hình đã được train trước đó sẽ được dùng để dự đoán nhãn cho văn bản.
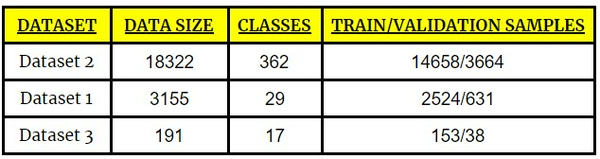
Phân tích dữ liệu:
Chúng ta sử dụng 3 loại dữ liệu với những nhãn khác nhau được shown ở bảng dưới đây:
Phân loại văn bản sử dụng Convolution Neural Network (CNN):
CNN là một class các mạng nơ-ron nhân tạo, feed-forward (nơi các kết nối giữa các nút không tạo thành một chu kỳ) và sử dụng một biến thể của multilayer perceptrons được thiết kế để yêu cầu tiền xử lý tối thiểu. Chúng được lấy cảm hứng từ vỏ não thị giác động vật.
Điều này tôi đã tham khảo
CNN thường được dùng trong lĩnh vực computer vision, tuy nhiên, gần đây nó đã được áp dụng vào các vấn đề về NLP và kết quả rất đáng mong đợi.
Hãy cùng xem nhanh qua chuyện gì sẽ xảy ra khi tôi sử dụng CNN trên dữ liệu văn bản qua biểu đồ dưới đây nhé! Kết quả của mỗi convolution sẽ được kích hoạt khi mà một mẫu đặc biệt được phát hiện. Bằng việc thay đổi kích thước của các kernels và ghép các đầu ra của chúng lại, bạn sẽ cho phép mô hình của mình phát hiện ra những mẫu có các bội số khác nhau (2, 3, hoặc 5 từ liền kề). Các mẫu có thể là các biểu thức (n-gram) ví dụ như là "I hate", "very good" và do đó CNN có thể nhận dạng chúng trong bất kể vị trí nào của chúng trong câu.
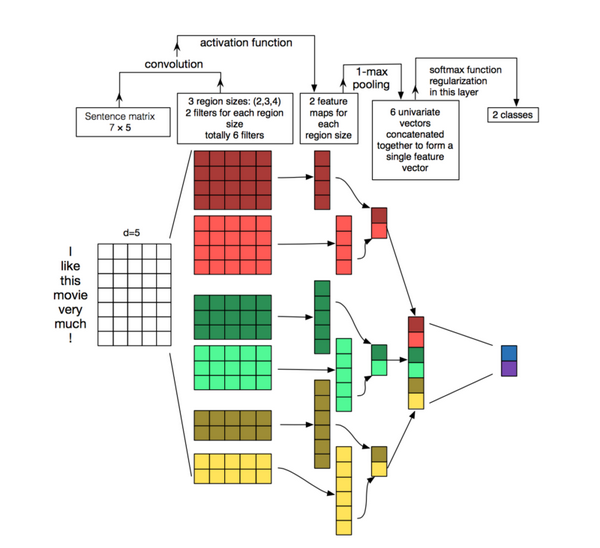
Trong phần này, tôi đã sử dụng một mạng CNN đơn giản hóa để xây dựng một trình phân loại, Trước tiên, tôi sẽ tiền xử lý dữ liệu bằng BeatifulSoup để xóa thẻ HTML và xóa những ký tự không mong muốn.

Dưới đây tôi đã sử dụng bộ từ điển
Đối với từ chưa có trong bộ từ điển, đoạn code dưới đây sẽ random một vector cho nó.
Dưới đây là một kiến trúc Convolutional rất đơn giản, sử dụng 128 bộ lọc với kích thước 5 và nhóm tối đa là 5 và 35.
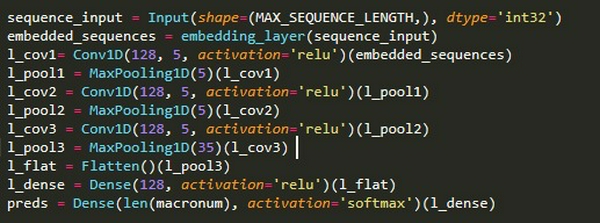
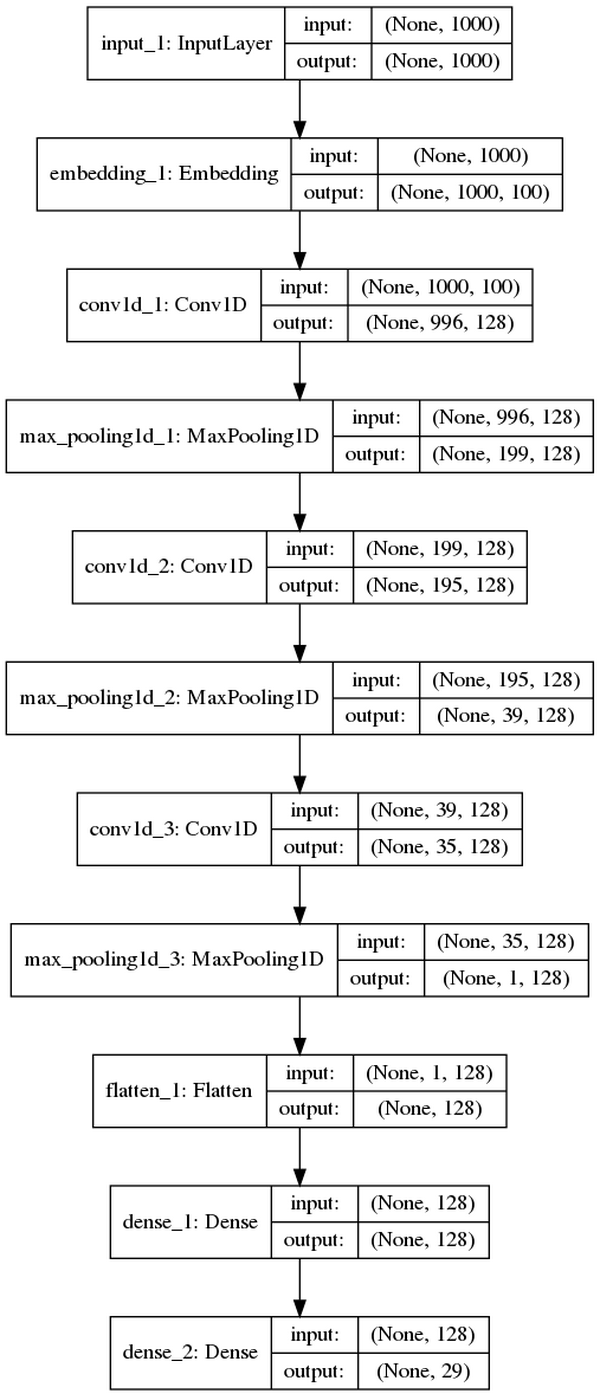
Dưới đây là cấu trúc Model CNN
Trên đây tôi đã trình bày cho bạn phần phân loại văn bản sử dụng CNN, các bạn hãy cùng thực hành theo đó nhé. Tôi sẽ tiếp tục viết Part 2 vào lần tới đây, các bạn nhớ theo dõi để có thể so sánh được giữa 3 mô hình nhé!
Tham khảo: Report on Text Classification using CNN, RNN & HAN