Áp dụng Multinomial Naive Bayes cho bài toán phân tích văn bản (Python)?


Một trong những ứng dụng phổ biến nhất của Machine Learning là việc phân tích và phân loại dữ liệu, đặc biệt là với dữ liệu dạng văn bản. Bài viết này sẽ hướng dẫn việc cài đặt một lớp phân loại nội dung văn bản sử dụng Multinomial Naive Bayes để phân loại tập dữ liệu 20 Newsgroups. Tập dữ liệu này bao gồm 18,000 bài viết chia thành 20 thể loại khác nhau. Các bài viết này sẽ được chia thành 2 tập training và testing theo một mốc thời gian cho trước. Các bạn có thể tải tập dữ liệu này tại đây:
Thư viện sử dụng
Dưới đây là những thư viên sẽ dùng trong bài viết:

Thống kê các thể loại
Đầu tiên, ta sẽ tính toán phần trăm số lượng bài viết của mỗi thể loại theo công thức:



Kết quả:
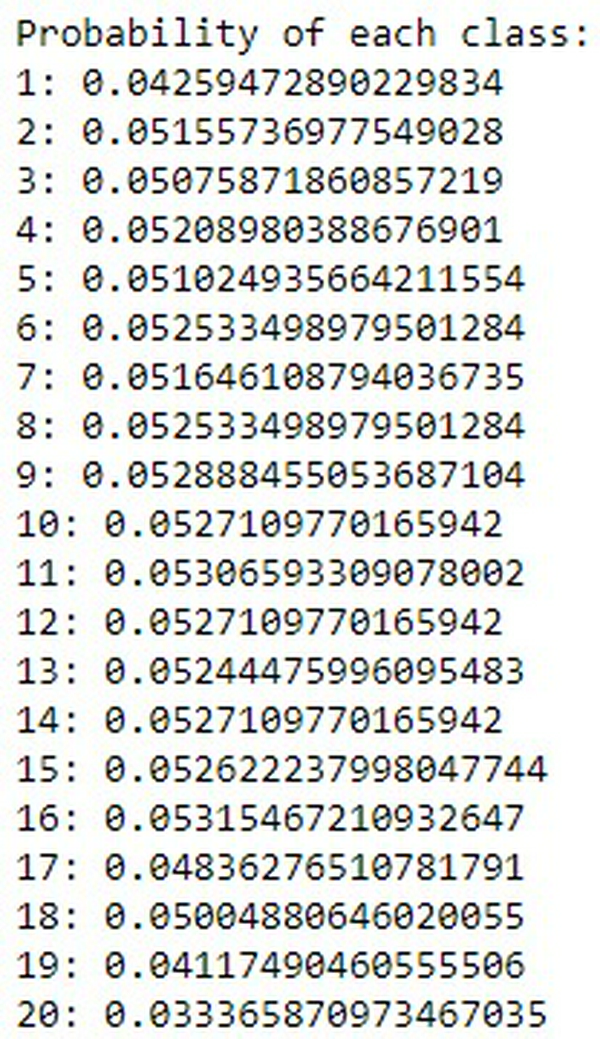
Phân phối xác suất qua từ điển
Đầu tiên ta tạo một Pandas Dataframe để chứa dữ liệu
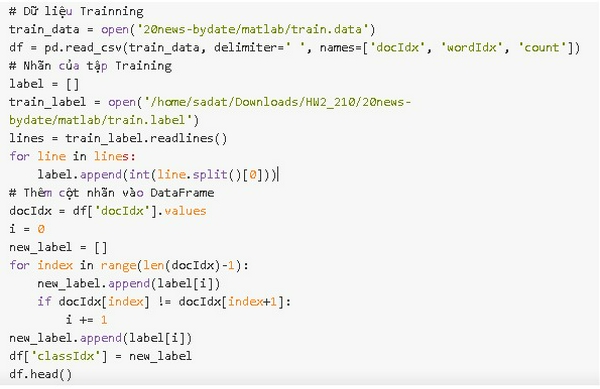
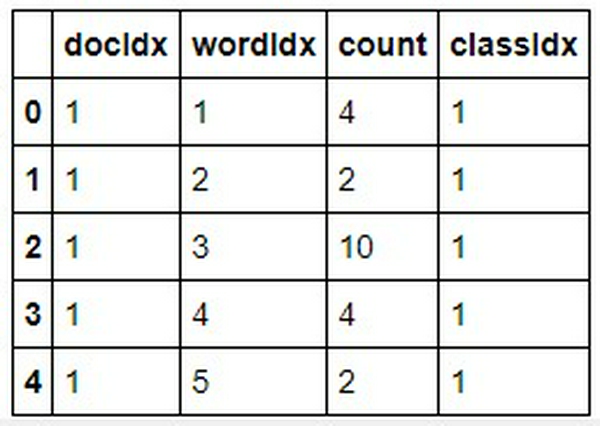
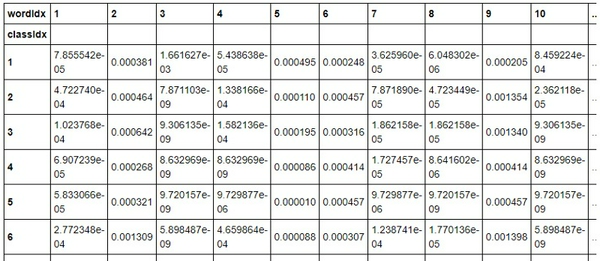
Xác suất xuất hiện của mỗi từ trong mỗi thể loại
Xác suất của 1 từ tại mỗi thể loại được tính như sau: Với thể loại j, xác suất của từ i là
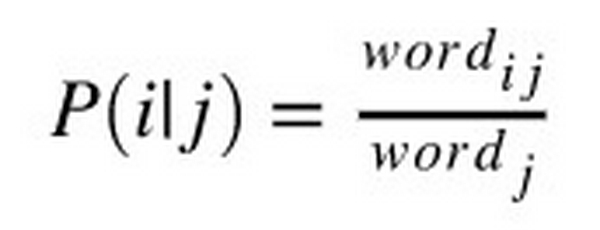
với wordi, j là số lần xuất hiện của từ i trong thể loại j, wordj là tổng số lần xuất hiện của từ i trong tập dữ liệu. Tuy nhiên, có một số từ sẽ chỉ xuất hiện ở một số thể loại nhất định nên xác suất các từ này ở các thể loại khác sẽ bằng 0. Để tránh điều này, ta áp dụng kỹ thuật Laplace Smoothing:
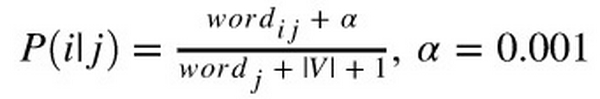
với V là từ điển chứa tất cả các từ.

Bảng xác suất sau khi tính toán có dạng:
Loại bỏ các từ không quan trọng (Stop words)
Là những từ có tỷ lệ xuất hiện cao nhưng đóng góp rất ít vào quá trình phân loại ( đại từ, giới từ, ...). Các stopword phổ biến như dưới đây, các bạn có thể copy list này vào script để sử dụng:
stop_words = [ "a", "about", "above", "across", "after", "afterwards", "again", "all", "almost", "alone", "along", "already", "also", "although", "always", "am", "among", "amongst", "amoungst", "amount", "an", "and", "another", "any", "anyhow", "anyone", "anything", "anyway", "anywhere", "are", "as", "at", "be", "became", "because", "become","becomes", "becoming", "been", "before", "behind", "being", "beside", "besides", "between", "beyond", "both", "but", "by","can", "cannot", "cant", "could", "couldnt", "de", "describe", "do", "done", "each", "eg", "either", "else", "enough", "etc", "even", "ever", "every", "everyone", "everything", "everywhere", "except", "few", "find","for","found", "four", "from", "further", "get", "give", "go", "had", "has", "hasnt", "have", "he", "hence", "her", "here", "hereafter", "hereby", "herein", "hereupon", "hers", "herself", "him", "himself", "his", "how", "however", "i", "ie", "if", "in", "indeed", "is", "it", "its", "itself", "keep", "least", "less", "ltd", "made", "many", "may", "me", "meanwhile", "might", "mine", "more", "moreover", "most", "mostly", "much", "must", "my", "myself", "name", "namely", "neither", "never", "nevertheless", "next","no", "nobody", "none", "noone", "nor", "not", "nothing", "now", "nowhere", "of", "off", "often", "on", "once", "one", "only", "onto", "or", "other", "others", "otherwise", "our", "ours", "ourselves", "out", "over", "own", "part","perhaps", "please", "put", "rather", "re", "same", "see", "seem", "seemed", "seeming", "seems", "she", "should","since", "sincere","so", "some", "somehow", "someone", "something", "sometime", "sometimes", "somewhere", "still", "such", "take","than", "that", "the", "their", "them", "themselves", "then", "thence", "there", "thereafter", "thereby", "therefore", "therein", "thereupon", "these", "they", "this", "those", "though", "through", "throughout", "thru", "thus", "to", "together", "too", "toward", "towards", "under", "until", "up", "upon", "us", "very", "was", "we", "well", "were", "what", "whatever", "when", "whence", "whenever", "where", "whereafter", "whereas", "whereby", "wherein", "whereupon", "wherever", "whether", "which", "while", "who", "whoever", "whom", "whose", "why", "will", "with", "within", "without", "would", "yet", "you", "your", "yours", "yourself", "yourselves" ]
Giờ chúng ta sẽ tạo Dataframe cho từ điển:

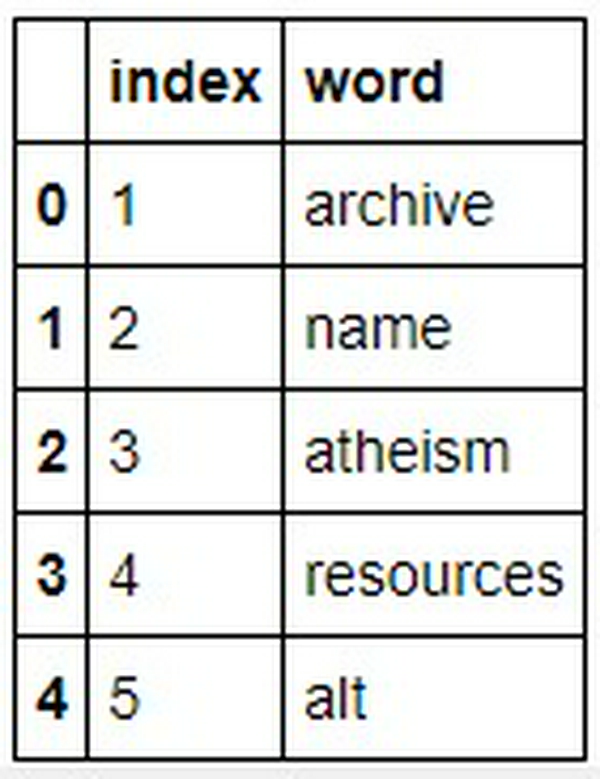
Lọc các stop words và đưa số lần xuất hiện của chúng về 0

Multinomial Naive Bayes Classifier
Kết hợp xác suất xuất hiện của các từ và tỷ lệ bài viết ứng với mỗi thể loại, ta có:
- Với thể loại j , từ i và tần số xuất hiện của từ fi trong j, ta có xác suất của thể loại j được tính:
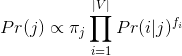
- Để tránh việc các xác suất quá nhỏ khiến việc tính toán không chính xác, ta logarit hóa công thức trên:
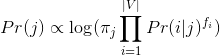
- Bỏ ngoặc
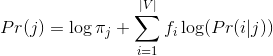
- Để tránh việc 1 từ xuất hiện nhiều lần trong 1 bài viết, ta lấy log của tần số xuất hiện của từ:
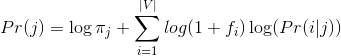
- Cuối cùng, ta thêm thông tin về Inverse Document Frequency (IDF) làm tham số cho từng từ:
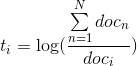
- Công thức cuối cùng:
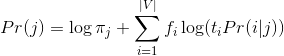
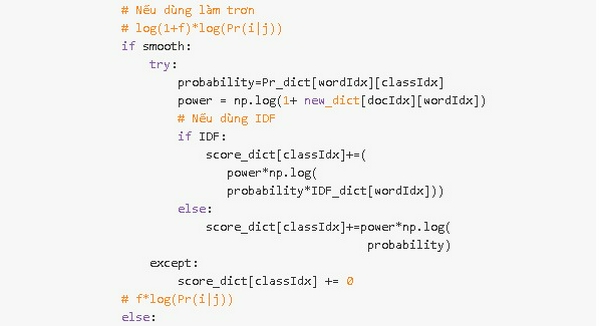
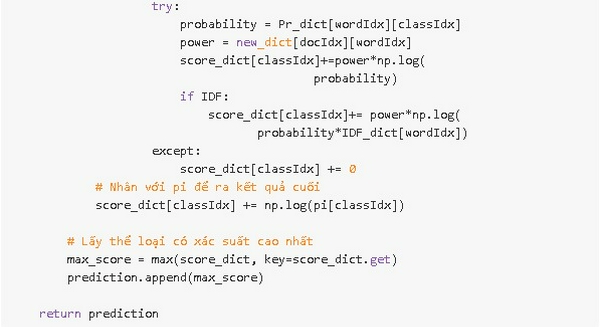
Code:


So sánh tác dụng của làm trơn và IDF:
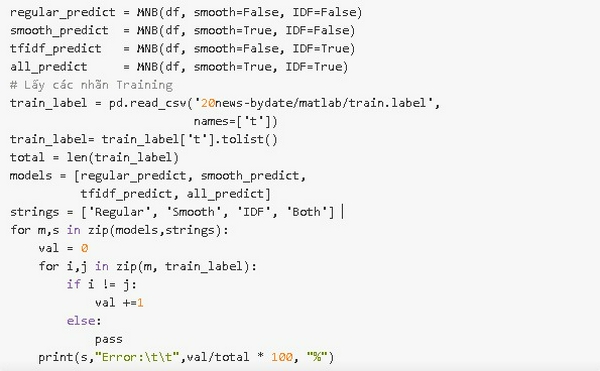

Có thể thấy, IDF không đóng góp nhiều cho quá trình phân loại, một phần vì ta đã loại bỏ các stop words. Việc sử dụng Laplace smoothing khiến cho mô hình dữ đoán chính xác hơn. Dưới đây là công thức tối ưu:
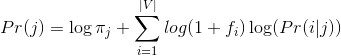
Đánh gía qua dữ liệu Test

Ta có tỷ lệ lỗi:
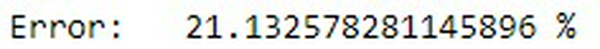
Ta có thể thấy được việc sử dụng Multinomial Naive Bayes cho kết quả khá tốt trong bài toán phân loại văn bản. Dù đã có nhiều mô hình và thuật toán có hiệu năng xử lý tốt hơn rất nhiều nhưng với tốc độ nhanh và không tốn nhiều tài nguyên để tính toán thì MNB vẫn là một sự lựa chọn không tồi chút nào. Cảm ơn các bạn đã đọc bài viết :D.
Nguồn : TowardsDataScience Multinomial Naive Bayes Classifier for Text Analysis (Python)